[Java] ArrayList 알아보기
특정 자료구조가 필요할 때 배열의 길이가 명확하지 않다면 주로 arrayList를 사용했다.
데이터를 앞에서부터 넣는다고 한다면 linkedList를 사용했다. (최신순으로 Queue의 느낌이 필요하다면)
깊이 있게 공부해 보고 싶어서 내가 제일 사용을 많이 하는 이 2개부터 파보려고 한다. 저 2가지 이유 이외에 보다 명확한 이유와 나 자신을 설득시키기 위해 오늘 공부해본 걸 작성해보고자 한다.
ArrayList를 그냥 내가 생각하는 느낌대로 Class를 작성해 구현해 보자.
(E 타입을 받아 제네릭 하지 않게 그냥 단순 숫자 배열로 만 작성해 보자.)
package datastructure;
public interface ArrayListInterface {
// 뒤에부터 추가
boolean add(int num);
// 인덱스 에 의한 추가
boolean add(int num,int idx);
// 처음 발견한 숫자 삭제
boolean removeByNum(int num);
// 인덱스 에 의한 삭제
boolean removeByIdx(int idx);
// 인덱스 로 값 가져오기
int get(int idx);
boolean isEmpty();
boolean contains(int num);
int size();
}ArrayList라고 하면 이 정도로 내가 제일 많이 사용하는 것 같다.
구현
package datastructure;
import java.util.Arrays;
public class GuiwooArrayList implements ArrayListInterface{
private int[] guiwoo;
private int total;
public GuiwooArrayList() {
this.guiwoo = new int[10];
this.total = 0;
}
@Override
public boolean add(int a){
expendArray();
guiwoo[total++] = a;
return true;
}
@Override
public boolean add(int num, int idx) {
if(idx >= this.size()) throw new ArrayIndexOutOfBoundsException();
expendArray();
int[] temp = new int[this.size()-idx-1];
System.arraycopy(guiwoo,idx,temp,0,temp.length);
System.arraycopy(temp,0,guiwoo,idx+1,temp.length);
guiwoo[idx] = num;
total++;
return true;
}
private void expendArray(){
if(this.size() == guiwoo.length){
int[] next = new int[this.size()*2];
System.arraycopy(this.guiwoo,0,next,0,guiwoo.length);
guiwoo = next;
}
}
@Override
public boolean removeByNum(int num){
int idx = -1;
for(int i=0;i<this.size();i++){
if(num == guiwoo[i]){
idx = i;
break;
}
}
return this.removeByIdx(idx);
}
@Override
public boolean removeByIdx(int idx){
if(idx == -1) throw new IllegalArgumentException("없어요");
int[] temp = new int[this.size()-idx-1];
System.arraycopy(guiwoo,idx+1,temp,0,temp.length);
System.arraycopy(temp,0, guiwoo,idx,temp.length);
total--;
return true;
}
@Override
public int get(int idx){
if(idx >= this.size()){
throw new ArrayIndexOutOfBoundsException("허용 인덱스 범위 초과");
}
return this.guiwoo[idx];
}
@Override
public boolean isEmpty(){
return this.size() == 0 ;
}
@Override
public boolean contains(int num) {
for(int target : guiwoo){
if(target == num) return true;
}
return false;
}
@Override
public int size(){
return this.total;
}
public String toString(){
return Arrays.toString(this.guiwoo);
}
}테스트
package datastructure;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class GuiwooArrayListTest {
@Test
void addTest(){
int target = 11;
GuiwooArrayList guiwoo = new GuiwooArrayList();
for (int i = 0; i < target; i++) {
guiwoo.add(i);
}
Assertions.assertSame(target,guiwoo.size());
}
@Test
void addNumByIdx(){
int targetNum = 100;
int targetIdx = 5;
GuiwooArrayList guiwoo = new GuiwooArrayList();
for (int i = 0; i < 5; i++) {
guiwoo.add(i);
}
Assertions.assertThrows(ArrayIndexOutOfBoundsException.class,
()->guiwoo.add(targetNum,targetIdx));
}
@Test
void addNumByidx(){
int targetNum = 100;
int targetIdx = 2;
GuiwooArrayList guiwoo = new GuiwooArrayList();
for (int i = 0; i < 5; i++) {
guiwoo.add(i);
}
guiwoo.add(targetNum,targetIdx);
Assertions.assertEquals(guiwoo.get(targetIdx),targetNum);
Assertions.assertEquals(guiwoo.size(),6);
}
@Test
void removeTestByNumber() throws Exception{
int target = 11;
GuiwooArrayList guiwoo = new GuiwooArrayList();
for (int i = 0; i < target; i++) {
guiwoo.add(i);
}
guiwoo.removeByNum(6);
Assertions.assertSame(guiwoo.size(),target-1);
guiwoo.add(15);
Assertions.assertSame(15,guiwoo.get(guiwoo.size()-1));
}
@Test
void removeByIdx(){
int target = 11;
GuiwooArrayList guiwoo = new GuiwooArrayList();
for (int i = 0; i < target; i++) {
guiwoo.add(i);
}
guiwoo.removeByIdx(6);
Assertions.assertSame(7,guiwoo.get(6));
}
}스프링 부트가 아닌 그냥 자바 프로젝트라서 라이브러리에 junit을 추가해줘서 테스트 코드를 돌렸다.
나름 예쁘게 작성해보고 싶어서 30분 정도 투자해서 코드를 작성한 것 같다.
특별할 것 없이 최초 생성 시 10 개의 배열 사이즈를 고정해서 사용하는 로직이다. 배열의 범위가 가득 찾을 때 확장을 시켜주는 로직이다.
이중 System.arrayCopy를 정말 많이 사용했는데 한번 살펴보자.
먼저 설명을 읽어보자.
length의 숫자만큼 src에서 가져와 dst로 복사한다.라는 첫 번째 문단이 있고 두 번째 문단을 보면 내 코드의 문제점 이 보인다.
동일한 src와 dst를 참조할 경우 자체적으로 copy를 실시해 내부적으로 수행이 된다는 의미이다.

즉 제거할 때 capacity의 변화가 없는 경우 라면 나의 코드처럼 temp 변수를 사용할 이유가 없어지는 것이다.
removeByIdx의 함수만 수정 후 테스트를 돌려보자.
이렇게 테스트 가 잘 통과되니 기분이 좋다.
계속해서 arrayCopy를 읽어보자. 어느 경우에 안되는지 에 대한 예시를 들어주고 있다. 배열이 아닌 경우, 인덱스 의 숫자가 - 인 경우 등등 (ArrayStroeException, IndexOutOfBounds,...)
@IntrinsicCandidate
함수를 보면 IntrinsicCandidate 어노테이션과, native라는 생전 처음 보는 친구들이 달려있다. 살펴보자.
instrinsic 내장함수 란 각 언어마다 컴파일러, 혹은 인터프리터 등이 있는데 이 두 친구들이 특별하게 핸들링하는 함수들을 지칭한다.
즉 최적화된 내장함수들을 의미한다는 소리이다.
다시 말해 low 한 레벨 어셈블리 어 같은 언어로 jvm에서 호출하는 것을 의미하는 것 같다.
다양한 글들을 읽어보면 significant performance benefits이라고 한다. 하나의 테스트를 예로 보여주는데 sqrt를 100k 번 하는 클래스 호출 함수와 내장 함수 의 속도 비교를 보여주는 데 무려 35%가량의 속도 차이가 발생한다.
심지어 JVM 마다 호출하는 경우가 있고 아닌 경우도 있다고 한다. 즉 저 어노테이션 이 있으면 low level 코드를 불러 최적화된 성능을 보여준다는 소리임과 동시에, 다른 JVM, OS 등에서 실행했을 경우 다른 성능을 보여줄 수 있다는 의미이기도 하다.
조심해서 사용해야 할 이유가 있다는 소리이다. 이런 low level 문제가 발생된다면 버그 찾기가 정말 어려워질 것으로 보인다.
한 블로그 포스팅에서는 우리가 종속성 및 런타임을 최신 상태로 유지해야 할 이유라고 말한다.
native
java native interface에서 구현된 함수를 지칭할 때 이 예약어를 사용한다.
C로 작성한 main에서 호출해보려고 이것저것 시도하다가 실패했다. 추후 go 언어로 함수하나 작성해서 컴파일해서 해볼 예정이다.
dll 파일 혹은 so 확장자의 파일이 필요하고 이걸 lib에 추가해야 System.load 가 가능한 것으로 보이는데 추후 도전해보자 오늘 목표로부터 너무 멀어졌다.
위와 같은 방식으로 arrayList를 구현해 보았다. 실제 구현된 코드를 보면서 차이점을 한번 살펴보자.
ArrayList를 가서 읽어보자.
가장 첫 줄에 List 인터페이스 의 크기조절 이 가능한 자료구조라고 설명 되어 있다. null을 포함한 모든 object를 받을 수 있으며 size manipulating 한다고 작성되어 있다. vector 자료구조 와 다른 점이라고 한다면 단순 동기화를 지원하지 않는다는 점이다.
저 단순한 동기화 지원하지 않는 것 때문에 arrayList의 자료구조 가 더 생긴 건가 라는 의문이 생긴다.
찾다가 흥미로운 글이 있어 작성한다. arrayList와 vector의 차이점 중 뚜렷한 부분 중 하나는 바로 최적화 부분인데 확장을 함에 있어
arraylist는 >>1 이 연산자를 이용해 50% 를 확장, vector는 100% 를 확장한다.
Synchronized 동기화는 좋은 작업인가 에 대한 의문점을 가질 필요가 있다. 물론 동기화 가 보장된다면 좋다고 생각할 수 있다. 그러나 동기화를 하는 데 있어 비용이 든다. 시간 혹은 메모리가 이 말은 즉 느리다는 소리다. 지난번 스트링 버퍼와 스트링 빌더 의 차이에서 볼 수 있듯이 동기화에 드는 비용은 커지면 커질수록 확연한 속도차이가 발생한다.
단일 스레드 의 경우 이런 동기화 비용을 지불할 필요도 없을뿐더러 위와 같은 확장성에 있어서도 불필요한 소요가 생긴다.
이런 부분에서 본다면 내가 작성한 커스텀 arrayList 매번 *2 만큼 확장하는데 말할 것도 없이 최적화가 필요한 부분이다.
이런 부분 때문에 새로운 프로젝트 라면 항상 arrayList를 사용할 것을 권장한다.
동기화 부분 은 컬렉션 함수로 아래와 같이 제공되어 arrayList 또한 동기화 작업을 진행할 수 있다.
Collections.SynchronizedList(arrayList);
add(int n) vs add(E e)
동일한 방법으로 뒤에 추가하면서 total size를 이용해가면서 추가한다. 사이즈 가 같다면 grow()라는 함수를 이용해 capacity를 증가시켜 준다. 이렇게 뒤로 항상 추가를 하게 된다면 평균 constant 시간 즉 o(1)의 시간 값을 소모한다고 판단해도 좋을 것 같다.
왜? 이미 증가한 배열에 [total++] 이런 식으로 디렉트로 넣어주면 된다.
*2 만큼의 사이즈 증가로 인한 속도의 차이가 궁금하니 100k 기준으로 테스트 코드를 돌려보자.

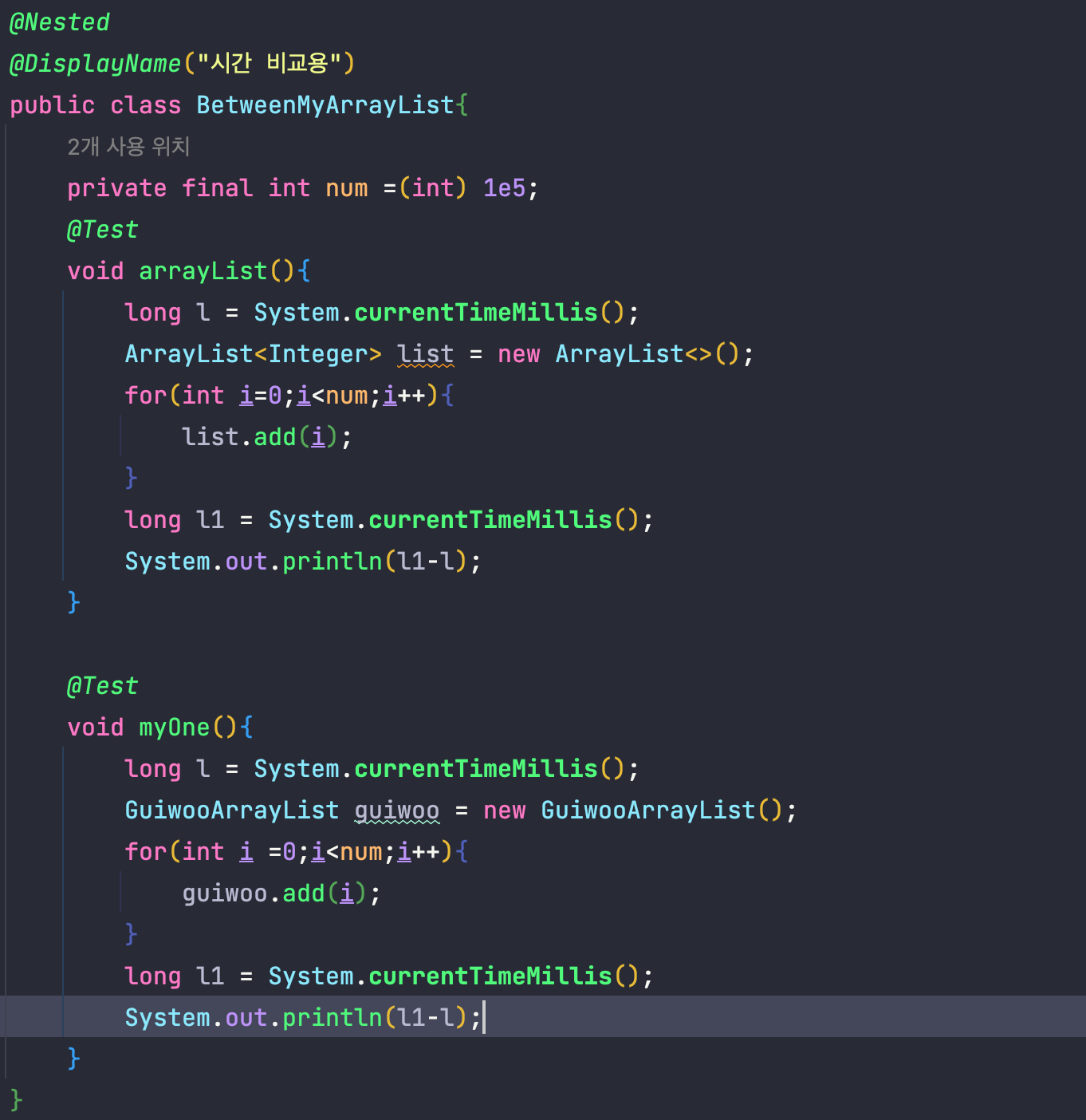
몇 번을 돌려도 그렇게 유 의미한 차이는 나지 않는다. 동일한 로직을 이용했기 때문인가 최적화 부분 에서 의 차이를 검증하기 위해
BenchMarkTest를 이용해 보자.

이렇게 벤치마크 추가해 주고(jmh.core, jmh.generator.annprocess)
간단한 클래스 만들어서 돌려주자. (추후 benchmark 블로그 포스팅도 하겠다.)
package datastructure;
import org.openjdk.jmh.annotations.*;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.AverageTime)
@State(Scope.Thread)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 10)
@Fork(1)
@Measurement(iterations = 100)
public class GuiwooBenchMark {
@Param({"10","1000000"})
public int size;
@Benchmark
public void arrayList(){
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
list.add(i);
}
}
@Benchmark
public void arrayListCustom(){
GuiwooArrayList list = new GuiwooArrayList();
for (int i = 0; i < size; i++) {
list.add(i);
}
}
}
mili 초에서 차이가 별로 없기에 나노 초 재확인했다. 여전히 나의 custom list 가 더 빠른 것이 확인된다.
grow()와 expend() 함수 의 최적화 차이 여부로 판별된다. 즉 최적화 간에 호출되는 함수 들에 따라 arrayList의 함수가 더 느리다는 결론이 나왔지만 아직 찝찝하다.
add(E el, int idx)
다만 이렇게 인덱스에 의해 추가가 되는 경우는 생각을 해보아야 한다. 중간 인덱스에 끼이면 arrayCopyOf를 사용해 중간에 추가해서 밀어 넣어주는 방식이다. 중간검증을 통해 grow 여부를 판별하고, 밀어 넣어주기 때문에 copy 될 배열의 for loop 한번 돌 시간이 필요하기 에 o(n) 시간이 소요된다.
get(int idx)
그렇다면 다시 말해 이렇게 get으로 뽑아온다면? 배열에서 디렉트로 뽑아오는데 당연히 o(1)의 속도를 보여준다.
isEmpty(), size()
이 두 친구 들은 클래스 내부적으로 필드를 가지고 있어 바로 호출하면 되기 때문에 o(1)의 속도를 보여준다.
remove(E el)
내가 작성한 것과 동일하게 최초발견된 오브젝트를 삭제한다. object 찾는 for loop 한번, 지우는 로직을 위해 arrayCopy 한번
통상 o(n) 시간복잡도를 가질 것으로 보인다.
remove(E el, int idx)
o(n) 시간복잡도를 가질 것이다. for loop을 이용해 탐색, arrayCopy를 통해 밀어줄 것들 복사해서 밀어준다면 동일한 시간복잡도가 나와야 한다.
contains(E el)
o(n) 시간복잡도를 가질 것이다. for loop을 이용해 탐색을 한다 다만 흥미로운 점은 arrayList 상에서는 indexOf(E el)을 이용해 > 0을 이용해 반환 값을 결정한다.
위에 구현한 함수 상에서 비슷한 로직을 이용해 arrayList 함수 또한 구현되어 있다. 이외에 궁금한 게 있으니 api documentation을 보자 가독성이 20000배 좋다.
놓친 부분으로는 addAll, forEach(), iterator(), etc... (https://docs.oracle.com/en/java/javase/19/docs/api/java.base/java/util/ArrayList.html)
list의 capacity 즉 size 최적화를 위한 trimToSize 도 존재한다. 신기한 함수다. 얼마큼 유동적인 listSize를 운용해야 메모리 낭비를 줄이기 위해 이 함수를 사용할지 느낌조차 없다.
(추가적으로 검색해보니 늘어난 배열에 대해서 가바지 컬렉터 에서 수거하거나, 줄이는 신비한 묘책이 없기때문에 이러한 함수가 제공된다.)
다만 웃긴 점이 하나 있는데 retainAll이라는 함수에서는 파라미터로 받는 컬렉션을 제외한 나머지를 삭제한다. 이때 batchRemove()라는 함수이름을 사용하지만, addAll 은 이런 게 없어서 아쉬웠다. removeAll, retailAll 이 2 경우 모두 사용하기 위해서 이렇게 함수로 뺀 것처럼 보이지만. 아쉬운 부분이긴 하다.
ArrayList 하나 알아보기 위해서 이렇게 시간을 오래 들여서 보니 부족한 게 너무 많아서 어디부터 손봐야 할지 모르겠다..
어렴풋이 나마 느꼈던 것이 맞았다는 기분이 들어 좋았고, vector 같은 쓰면 안 되는 이유, synchronized 하지 않는 이유 등 모른 부분을 보다 명확히 알게 돼서 나름 보람찬 공부였다.
상수시간 을 가지는 add, size 등 을 자주 사용하게 된다면 비교할것도 없이 ArrayList 를 사용하면 된다.
그게 이 ArrayList 자료구조 가 의 존재 이유라고 생각된다.