늦었지만 25년도 회고를 해보고자 한다.
실제로 24년 10월에 입사한 회사에서, 제대로 적응하고 무언가를 시도해본 해가 25년이지 않았나 싶다.
23년 2월부터 개발자를 시작해 26년 1월까지 약 3년의 기간 동안 정말 많은 변화가 있었는데, 그중에서도 25년의 변화가 가장 크지 않았나 싶다.
25년에는 사내 Vuex라는 플랫폼을 개발하는 데 전력을 기울였다. 회사와 팀의 지원이 있어 어느 정도 결과물을 낼 수 있었고, CES에서 시연하는 모습을 볼 수 있었다.
개발 환경의 변화
사실 개발 환경의 변화가 엄청났다. 나만의 커스터마이징을 시작한 한 해이지 않았나 싶다.
팀장님의 영향이 컸다. 본인의 개발 커리어 동안 필요한 모든 환경을 집어넣은 커스텀된 환경이 회사 입사하자마자 주어졌다.
신세계였다. 이렇게 편한 툴들이 있는지도 몰랐고, 찾아볼 생각조차 하지 못했다.
이런 커스텀이 주는 매력에 매료되었고, 나만의 개발 환경에 대한 욕심이 조금 생기기 시작했다.
Code Editor의 변화
Visual Studio Code → GoLand(IntelliJ) → Cursor → Neovim
처음 개발을 배울 때는 VS Code로 시작했고, 첫 회사에 입사했을 때는 GoLand가 제공되었다.
25년에는 엄청난 AI 발전에 따른 Cursor의 Tab 기능이 정말 충격적일 정도로 좋았다.
그럼에도 위 모든 것을 버리고 Neovim을 최종적으로 사용하고 있는 이유는 주변 환경의 영향이 컸다.
Cursor 같은 정말 좋은 툴이 있는데 왜 팀장님과 사수님은 아직까지 Neovim을 사용하고 있을까? 라는 의문에서 시작했고,
Cursor에게 빼앗긴 코드 작성의 즐거움을 되찾기 위해 Neovim을 과감하게 선택했다.
LazyVim 기반의 미니멀한 세팅을 구성했고, fzf-lua를 비롯해 LSP 등을 세팅한 현재의 결과물은 다음과 같다.
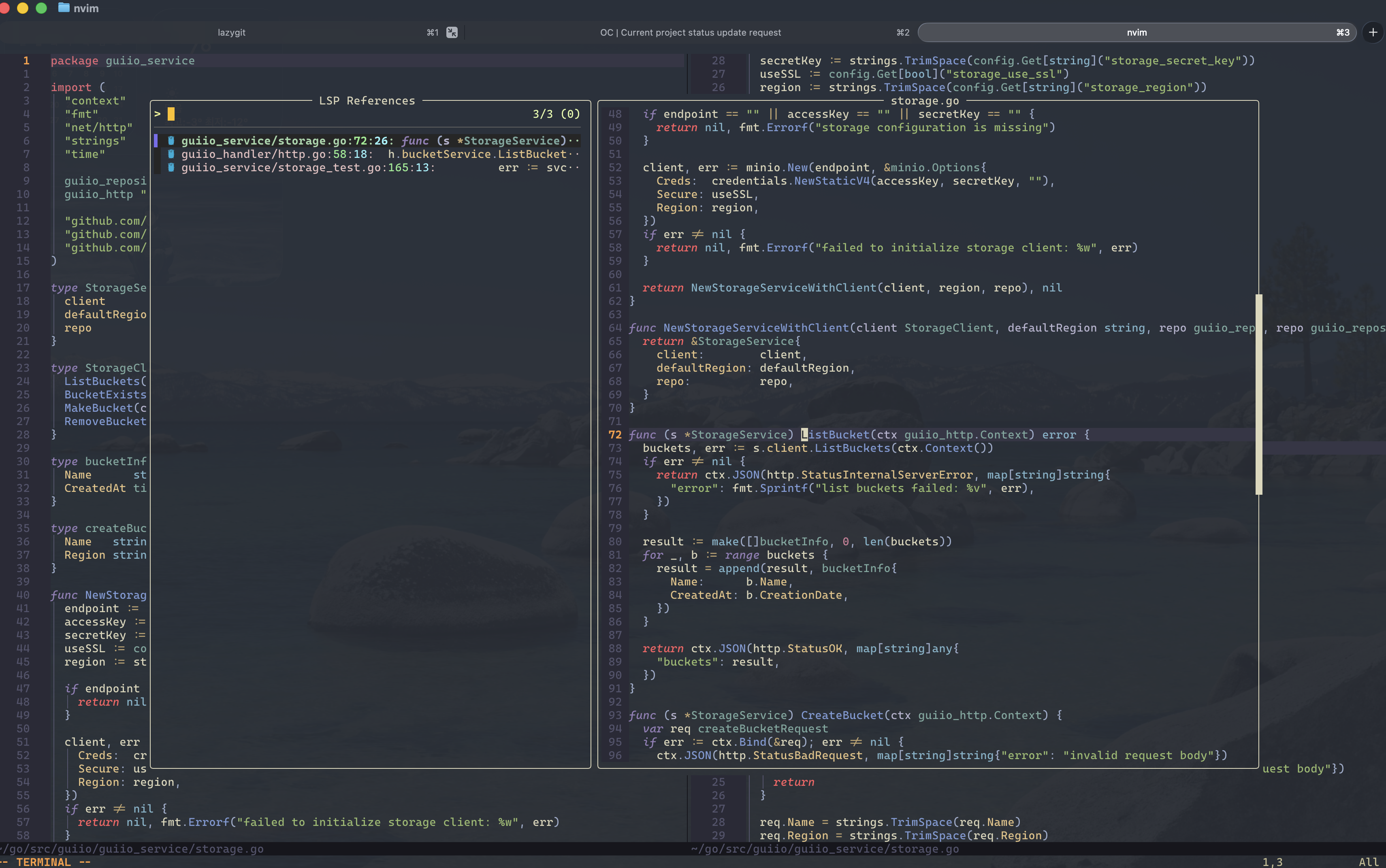
Terminal의 변화
Neovim 세팅을 하면서 터미널 또한 사용하던 iTerm2에서 Ghostty로 옮겨갔다.
팀에서 사용하던 iTerm2에는 다양한 세팅과 함께 tmux를 붙여 화면 분할, 세션 공유, Vim Copy Mode 등을 이용하고 있었는데,
생각보다 버벅이는 느낌이 없지 않아 존재해 Ghostty로 이동했다.
tmux 없이 Ghostty 기능만으로도 강력한 기능들이 제공되며, 무엇보다 빠릿빠릿한 반응성과 다양한 테마 제공이 정말 마음에 들었다.
각종 Tool의 변화
- Zsh 기반으로 다양한 함수들을 작성해 사용하고 있다. 특히 Zoxide는 가장 많이 사용하지 않나 싶다.
이동했던 경로를 기억해 c myFolder → cd ~/somewhere/a/b/c/myFolder로 이동시켜주는 기능인데, 정말 한 번쯤은 사용해보라고 권하고 싶다.
그 외에도 JWT parser를 비롯한 각종 util 함수들을 zsh에 등록해 사용하고 있다. - LazyGit Tui기반의 Git 관리 툴이다.
TUI 기반의 Git 관리 툴이다. 간단한 Git 기능들을 비롯해 커밋 내용과 메시지를 보기 정말 편하다. - RayCast
다양한 앱에 대한 단축키 설정을 할 수 있고, Rectangle 기능이 내장되어 있어 많이 사용하고 있다. - Karabiner
키 매핑 툴인데, 원하는 단축키들을 등록해 사용하고 있다.
특히 마우스 이동, 휠 이동, 왼손으로 사용하는 numpad, vim mode 등 다양하게 매핑해 사용 중인데, 없으면 고장 날 정도로 종속된 상태다. - AI Tool
Web, OpenCode, Crush를 이용하고 있다. 전반적으로 터미널 환경으로 구성하다 보니 아무래도 TUI가 더 편하다.(Claude는 현재 Auth가 막혀 API 키 발급이 필요하고, 비용이 너무 비싸다.)
단순한 질문은 팀 Gemini를 통해 하고 있고, OpenCode는 OpenAI를 사용 중이다.
전반적으로 GUI 환경에서 TUI 환경으로 넘어가며 다양한 세팅을 하게 된 한 해이지 않았나 싶다.
TUI 환경을 구축하다 보면 나만의 환경을 만드는 게 정말 재미있다.
요즘은 우스갯소리로 “터꾸(터미널 꾸미기)” 한다고 종종 팀원들과 이야기한다.
개발
25년에는 Vuex라는 제품군 개발에 심혈을 기울였다. 아무것도 없는 상태에서 해당 플랫폼을 개발하려다 보니 정말 다양한 문제를 겪지 않을 수 없었다.
- Go 언어라는 특성상 Java Spring 진영만큼 획일화된 프레임워크가 없고, 각자의 개인적 특성을 지닌 상태이다 보니 각자가 생각하는 도메인의 영역이 달랐고, 이렇게 다른 상태에서 시작되는 개발은 당연히 오차가 발생할 수밖에 없었다.
다만 DDD의 감을 잡아가며 도메인의 컨텍스트를 어디까지 정할지 기준이 생기고 나서부터는 무언가 합이 맞아간다는 느낌이 들었고, 정말 즐겁지 않을 수 없었다.
정말 많은 코드 리뷰와 나의 생각을 정리하는 시간을 가지게 되었고, 이쯤부터는 코드 작성보다는 생각과 AI와의 대화를 더 많이 하게 된 것 같다. 플랫폼 팀의 고도화된 프레임워크에 적응하는 게 생각보다 어려웠다.
- Contributor 작업을 처음 해보게 되었다.
해당 라이브러리를 사용해야 했는데 우리가 원하는 기능이 없어 깃 포크를 진행했고, 우선 작업한 뒤 PR을 통해 첫 컨트리뷰터가 되었다.
대형 Star가 박힌 프로젝트에 나의 PR이 main에 머지된다는 건 정말 짜릿한 경험이었다.
- SQL 튜닝 예를들어 특정 테이블의 하나의 칼럼값의 데이터가 너무 많아 발생한 SlowQuery는 Explain상에서 발견하기 어려웠다.
왜? ref Const 이고 Where도 index가 적용되는데 이게 왜이럴까? DB의 메모리풀을 의심하고 나중에는 DB 성능까지 의심하기 까지 이르렀다. 다시 돌아와서 데이터의 칼럼이 너무 많아 발생되는 단순 네트워크 문제였음을 확인했을때 정말이지 너무 바보같았다.
DB SlowQuery의 성능 문제를 단순 인덱스가 아닌 네트워크 대역폭, 메모리 버퍼등 시야를 보다 확장하는 계기가 되었으며, 다시한번
실행계획이 전부는 아니다 라는 사실을 진짜 뼈저리게 느낀 순간이지 아닌가 싶고, 테스트의 범위 폭을 좀더 넓히게 된 계기가 아닐까 싶다.
- 우리의 배치시스템은 Batch MQ를 통해 MQ에서 Batch를 발행하는 구조로 되어있고 이 Batch에서는 각 서비스에 등록된 함수들의 포인터 정보를 가져와 함수 포인터를 호출하는 구조이다.
어느날 특정 작업이 동작하지 않는 이슈 리포트가 올라왔고 로그를 탐색해본 결과 MQ가 소구되지 않던 이슈가 있었다.
왜그런걸까 파악하는데 정말 많은 시간을 소모했다.
MQ를 통해 Batch가 실행되고 해당 Bacth 함수의 호출 결과가 발생되어야 MQ Subscribe가 다음 메세지를 수신할 수 있는데,
해당 Batch에서 Code Block이 걸리고 Release 하지 않는 이슈가 존재하여 해당 Batch Pipeline이 막혀버려 문제가 발생되었다. MQ의 Ctx Timeout을 사용하지 않은 문제 보다 근본적인 Batch 에 넘겨진 포인터 함수에서 Code Block이 걸린 근본적인 이유 특정 파일 업로드 할때 GoRoutin을 열고 회수하지 못해 wait가 걸려 Code Block이 발생된건데 이런 복합적인 이유가 발생되어 버그 파악이 생각 보다 힘들었다.
사실 위에서야 MQ와 Batch Pipeline 형태에 대해 적었지만 개발 당시만해도, 단순하게 사용만 하면 됐지 라는 안일한 생각 때문에 발생하게된 버그이지 않을까 싶다.
- 설계의 오류에 따른 나비효과를 경험했다.
위의 다양한 이유와 자잘한 이슈들을 경험을 하면서 상당히 보수적인 개발을 하고 있었다.
해당 Table에 통계가 적재되어야 하는데 유저 * 작업량 * 시간당 작업량 이런식으로 계산하여 테이블이 이렇게 되고 로우가 대충 이정도 쌓일 테니 모든 row를 기록하기 보단 시간단위가 최소 단위이니 시간별 upsert를 진행하자 라는 생각이 엄청난 스노우볼을 굴려왔다.
유저의 특정 작업이 디비의 부하를 많이 일으키다 보니 저런 메트릭 데이터를 적재함에 있어서 Dirty flag를 작업하고 해당 플래그를 기준으로 계산해서 집어넣자! 라는 생각이 DB 트랜잭션의 꼬임이 되어버렸고 결국 신뢰성 없는 통계 데이터가 되어 버렸다.
사용자의 행동 기반으로 데이터를 적재하는것이 아닌 DB의 트랜잭션 단위의 설계가 필요했는데 이게 안되다 보니 점점 더 괴랄한 형태의 통계를 적재하는 방식이 되어버렸고, 이제는 내가 아니면 손볼 수 없는 지경에 까지 이르게 되었다.
리팩토링 계획을 세우고 있는데 사용자의 작업마다 Delay Batch에 집어넣어, 해당 배치가 실행되기 전까지 존재하는 모든 값들을 하나의 형태로 합쳐서 특정 시간단위 flush를 진행해볼까 한다.
설계 오류에서부터 시작해 그 오류를 수정하기 위해 잘못된 탑을 쌓는 데 너무 많은 시간을 할애했고, 팀원분들, 나아가 사용자분들께 정말 죄송했다.
- 이미 서비스 중인 소프트웨어의 스키마 변경에 따른 업데이트는 지옥이었다.
최초 설계가 잘못된 위와 비슷한 문제이긴 했다. 사내 특성상 ai로 감지할 수 있는 Label의 목록들이 정해져있다고 성급하게 판단한 문제였다. 그결과 단순하게 칼럼을 추가하여 해결했다. 예를들어 red , blue, green 만 있다고 생각하고 기존 테이블 칼럼에 red, blud, green을 추가해버리고, 통계, 메트릭 모든 곳이 저 red blue green에 종속된채 통계들이 잡히고 있는 상태였다. 그러나, 추가가 필요하다는 내부 회의결과가 나왔고 각 유저별로 다른 label들이 표현되어져야 한다고 하는 미쳐버린 요구사항이 들어왔다.
이에 따라 테이블 분리 작업과 프론트와 협업하는 작업이 필요하고 기존 api 와 호환 가능하도록 작성을 해야했던 문제가 있었다.
Unleash 기반의 Feature Flag 기능을 이용해서 기능별로 묶고있지만 이 테이블 분리에 따른 스키마 변경은 진짜 Unleash를 떠나서 모든 서비스 레이어에서부터 모델 Entity 까지 전부 변경이 필요하게 되었다.
이건 미친듯한 작업량이었고 로직 단위에서 칼럼에서 분리해서 테이블로 옮긴다 말은 쉽지만 내부에서 해당 로직들에 의해 변경되는 모든 부분에 대해 세밀하게 파악이 필요했는데 이게 너무 곤란하고 난감했다. api 응답으로 내려주는 값들도 새로운 버전 이후 버전 모두 호환 되어야했고 테스트를 비롯한 모든 작업에서 상당시간 할애했고, 결국 이모든 제약사항 덕에 기존버전 호환 없이 일괄 업데이트를 진행하게 되었다.
상당히 아쉬웠다. 대부분의 작업을 기존 버전 호환되게 작업을 마무리했는데 시간적인 여유가 부족하고, 프론트 엔드 작업자와 호흡이 잘 맞지 못해 이런판단이 내려졌다는 사실이 조금 아쉬웠다.
근본적인 문제는 데이터 설계에 있었고, RDB의 이점을 잘못된 방법으로 사용하면서 편법으로 이용하고자 했던 나의 문제였다고 생각한다.
- OAuth 인증의 극치를 경험했다.
최초 사내 서비스를 목적으로 개발되어 Google OAuth를 이용하고자 했으나 AWS 환경, MinIO 등 다양한 플랫폼들이 붙으면서 통합적으로 유저가 관리될 필요가 있었으며 그결과 AWS Cognito 를 활용하기로 결정했으며 Google의 OAuth, MinIO IDP 등 다양한곳 에서 IDP인증을 제공해주고 있어 Cognito를 통한 유저관리는 정말 쉬웠으나 이게 서비스가 글로벌로 퍼지다 보니 동일한 유저에 대한 Federation 작업이 생각보다 애를 먹었고, Cognito의 Group을 이용하여 유저의 Federation 또는 서비스 지역에 대한 기록을 이용하고 있다.
또한 AWS Cognito를 사용하고 있어 Identity 발급을 이용해 다양한 서비스에 접근이 가능하다. 이말은 다시말해, 우리의 AWS 계정이 아닌 고객들의 AWS 계정에서 사용가능한 S3 버킷 목록을 우리의 로그인 시스템을 활용하여 로그인하여 사용할 수 있다는 의미이다.
AWS Cogntio를 통한 결정은 최고의 선택이 아니지 않은가 싶었다.
AWS Cognito에 토큰을 수정하는 Lambda 트리거 함수를 이용하여 토큰의 데이터를 수정할 수 있지만 로그인의 성능을 고려하여, 해당 기능을 제거하고, UserAttibute로 이전하는 등의 성능 개선을 했던 경험도 나쁘지 않았다.
다만 Cognito 자체에 너무 의존적인 상태가 되어있어 만약 우리의 서비스를 로컬 시스템에서 사용한다고 할때 어떻게 해당 Token 인증 로직들을 해결할것인지에 대한 고민이 있고, 거기에 까지 도달한다면, IDP를 인증해줄수 있는 서버를 추가적으로 구축해야하지 않을까 싶다.
- CloudFront를 통한 Cache 활용 극대화
Object Storage를 활용하고, 데이터의 용량이 생각보다 크다 개당 20MB 평균 10000개 정도 존재할 수있는 오브젝트들에 대한 값이 유연하게 Client Cache 적용전략이 필요했다.
us-east 즉 미국 타겟으로 cloudfront를 적용하고, MinIO용 cloudfront, seoul용 cloudfront 등을 이용하고 있었으나. 하나로 합칠수 있지 않을까 고민했고 uri prefix를 통해 하나의 CloudFront로 결합하여 비용을 1/3로 줄였으며 생각보다 뿌듯했다.
edge Lambda 들을 통해 요청에 대한 Validation, LoadBalance 기능들을 통합하였으나 해당 부분도 lambda의 cold start의 성능적이슈가 고려되어 cloudFunction에서 단순한 Validation 체크, EdgeLambda에서 Origin Request 전 Signing 처리, url 조작등을 처리하도록 분리하여, 위조된 요청은 Edgelambda 이전 , CloudFunction에서 모두 Validation 되도록 처리하는 경험은 생각보다 좋았다.
다만 우리가 사용하는 JwtToken을 이용하여 CloudFront 조회하는 로직상에 cloudFuction에서는 단순 Validation을 체크하고, origin Request Edge lambda에서는 라우팅 처리와, Signing 을 위한 작업을 진행하고 있었으나, Jwt의 검증은 CloudFront 성능상 제거를 했다. 해당 부분을 어떻게 검증을 해야할지 기술적 부채로 남아있다.
코드 베이스의 경우 관리도 하나의 기술적 부채로 남아있다. 팀은 Go 기반이 였으나 edge lambda의 경우 Javascript, 몇몇 lambda들은 Chalice를 이용한 Python 버전 관리를 하고 있는데 하나의 레포지토리 안에 모든 lambda를 밀어넣고 go, Javscript의 경우 shell script를 통한 배포 그외는 chlaice 이다.
최대한 언어의 다중성을 배제하고 go 로 마이그레이션 하는 작업이 필요하다고 생각한다.
다양한 부분에 있어서 개발 경험을 하지 않았나 싶다.
정말 좋은 팀리더 밑에서 좋은 동료들 덕분에, 나에게 주어진 과분한 과제들을 해결할 수 있지 않았나 싶다.
사실 웃으면서 넘긴 크고작은 버그들과 설계적 오류들이 존재하고 있으며, 그 기술적 부채들을 해결하고 있는 26년이 될것이라 생각된다.
서비스의 안정성과 신뢰성을 26년에는 목표하고 싶으며, 버그에 대한 고민보다는 최적화에 대한 고민을 하는 26년의 한해가 되었으면 좋겠다.