항상 Json의 데이터를 가지고 엔코딩, 디코딩을 할 줄 알았다. 특별한 값에서 오는 바이너리 데이터를 디코딩하고 성능개선의 과정에 대해서 작성하고자 한다.
1. go tool pprof 활용하기
- 성능개선을 위해서는 성능을 개선하기 위한 프로파일링 결과가 필요하다. Go에서는 tool로 아주 쉽게 제공해 준다.
- pprof을 설정한다. 단순하게 import 해주고, pprof으로 접근할 수 있는 포트를 제공해 주면 된다.
import _ "net/http/pprof"
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()

해당 페이지로 접근하면 위와 같은 이미지로 볼 수 있다.
좀 더 손쉽게 보기 위해서는 graphviz를 설치하면 손쉽게 확인할 수 있다.
- brew install garphviz
- go tool pprof -http 0.0.0.0:[그래프로 확인할 PORT] http://0.0.0.0:6060/debug/pprof/profile


1분간 profile 데이터를 모으고, 제공된 포트로 web 형태를 제공한다. 위에 제공된 이미지들은 graph, flame graph이다.
CPU 작업시간, 메모리 할당 등을 확인할 수 있다.
- 위의 툴과 benchmark test를 같이 이용하고 있다.
func Benchmark테스트명(b *testing.B){
for i:=0; i<b.N; i++ {
// 벤치마크 테스트를 진행하고자 하는 작업 수행
}
}
실행을 하면 아래와 같은 결과를 보여준다.
BenchmarkMyFunction-8 5000000 300 ns/op 64 B/op 2 allocs/op
- 5000000 벤치마크가 실행된 횟수
- 300 ns/op 반복에 소요된 평균 시간
- 64 b/op 반복에 할당된 메모리 바이트
- 2 allocs/op 반복당 메모리 할당 횟수
위 2가지 도구를 활용하여 성능을 개선하고자 한다.
2. 현재상태 파악
- 프로파일링 결과를 확인해 보면 다음과 같다.

binary Read에서 생각보다 많은 cpu 점유와 메모리 할당을 진행하고 있다. 성능개선의 포인트라고 생각한다.
- 벤치마크 결과

파싱 하나 하나 하는데 힙메모리 할당이 엄청나게 많이 일어나고 이는 gc가 수거할게 많아 성능의 문제가 될 지점이라고 생각한다.
3. Binary Read는 왜 많은 CPU 점유시간을 가질까?
- binary Read 함수 내부 구현을 확인하면
func Read(r io.Reader, order ByteOrder, data any) error {
if n := intDataSize(data); n != 0 { // 들어온 데이터의 사이즈를 설정하고,
bs := make([]byte, n) // 설정된 숫자만큼 바이트 슬라이스를 생성한다.
if _, err := io.ReadFull(r, bs); err != nil { // 제공된 reader로 부터 정해진 바이트 슬라이스만 읽는다.
return err
}
switch data := data.(type) {
// 타입에 맞춰서 data에 넣어주는 작업
}
}
v := reflect.ValueOf(data)
size := -1
switch v.Kind() {
case reflect.Pointer:
v = v.Elem()
size = dataSize(v)
case reflect.Slice:
size = dataSize(v)
}
if size < 0 {
// 에러처리
}
d := &decoder{order: order, buf: make([]byte, size)}
if _, err := io.ReadFull(r, d.buf); err != nil {
return err
}
d.value(v)
return nil
}
- Read 내부는 우선 전달받은 데이터가 원시타입의 경우라면 switch case를 통해 필터링된다.
- 이후 io.Reader 인터페이스의 ReadFull을 통해 전달받은 버퍼의 사이즈만큼 읽어오게 되고
- reflect 패키지를 활용하여 구조체가 전달된 경우의 케이스를 해결한다.
따라서 원시타입의 경우라면 값의 검증을 위해 2번의 검증을 하게 되고 이것이 반복된다면 2배의 연산을 더 진행하게 되는 것이다.
파싱 하고자 하는 데이터는 모두 숫자로 이루어져 있기 때문에 이는 부적절한 함수 사용이다.
binary.LittleEndian의 변수를 보면 ByteOrder의 인터페이스를 모두 제공하고 있으며 내부연산은 모두 비트연산을 통해 메모리 할당 없이 반환하고 있다는 것을 확인했다.
binary.Read -> binary.LittleEndian의 함수호출 변경 벤치마크 테스트
- 실행횟수 160 -> 646
- 한 번의 작업당 시간 7416761 -> 1952116
- 메모리 할당 136005 -> 2
저 메모리 할당이 비약적으로 줄어들며 전체적으로 성능이 많이 올라갔다.
프로파일링 결과를 보면

binary.Read의 CPU 점유와 힙메모리 할당이 완전히 사라졌다.
4. 자주 계산되는 항목들은 메모리 캐시 처리
모자이크 된 부분의 주된 계산은 sin, cos의 값을 구하는 것이다. 매 루프마다 특정 포인트의 x, y, z 축에 대한 sin, cos 값이 계산이 되는데
생각보다 cpu 연산과 딜레이가 되는 것 같아 고정적으로 반복되는 부분들은 구조체 선언과 동시에 sin, cos의 값을 미리 계산해서 처리했다.
모든 값에 대해서 캐시 처리를 하지 않은 이유는 어느 정도 참조가 덜된다 싶으면 메모리 해제를 통해 메모리의 여유를 두어야 하기때문에 해당 부분을 구현하기 까지 시간이 조금더 필요하여 필수 값들에 대해서만 어느정도 미리 계산을 진행했다.
벤치마크 테스트
- 실행횟수 646 -> 998
- 한 번의 작업당 시간 1952116 ->
1252630
- 메모리 할당 2 -> 3
메모리 할당이 늘어난 것은 배열로 캐시처리를 진행해서 그렇다.
5. 구역을 나누어 Go Routine 처리
파싱 되는 부분은 이차원 바이트 배열로 for 반복문을 통해 작업이 처리되고 있다.
따라서 각 for 반복문을 독립적인 시행영역이라고 생각한다면 아래와 같은 그림으로 변경할 수 있다.

벤치마크 테스트 결과
- 실행횟수 998 -> 2809
- 한 번의 작업당 시간 1252630 -> 577930
- 메모리 할당 3 -> 1005
확실히 어느 정도 메모리를 할당해야 성능향상을 기대할 수 있는 것 같다.
프로파일링 결과

최초 보였던 프로파일리의 결과보다 작업이 많이 줄은 것을 확인할 수 있다.
성능개선이 생각보다 괜찮게 되었다. 다만 마지막 개선작업의 go routine은 개발기에 적용하여 안정적인 평균속도를 제공해 줄 수 있는지는 지속적으로 확인해봐야 한다.
1. 보통 100~150ms 단위로 약 500개의 패킷이 전달된다. 그렇다면 위의 방식대로 동작한다면 순간 최대 고 루틴은 500+&가 될 수 있다는 사실이다.
2. 현재는 하나의 데이터 원천으로부터 가져오지만, 추가될 가능성이 있다는 부분
3. 1~2번의 사실을 고려했을 때 최대 고 루틴의 Pool을 두어 파싱에 사용되는 go routine의 숫자를 관리할 필요가 있다고 생각한다.
번외로 go의 standard 패키지 json의 Marshaling과 UnMarshaling이 생각보다 성능이 좋지 않다는 사실을 알게 되었다.
테스트 코드
type Address struct {
City string
ZipCode string
PostCode uint32
CountryCode uint16
CityCode uint16
People uint8
}
func BenchmarkJsonParser(b *testing.B) {
seoul := Address{
"Seoul", "117128", 11731, 82, 02, 128,
}
byteData, _ := json.Marshal(seoul)
b.Run("Standard Json Marshal", func(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
json.Marshal(seoul)
}
})
b.Run("Json Library Marshal", func(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
fastjson.Marshal(seoul)
}
})
b.Run("Standard Json UnMarshal", func(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
json.Unmarshal(byteData, &seoul)
}
})
b.Run("Json Library UnMarshal", func(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
fastjson.Unmarshal(byteData, &seoul)
}
})
}
위와 같이 단순한 구조체를 벤치마크를 돌렸을 때
| 실행횟수 | 평균 작업 속도 | 평균 메모리 사용량 | 평균 메모리 할당 횟수 | |
| Standard Library 마샬 | 6411848 | 165.5 ns | 144 byte | 2 |
| Go-Json 마샬 | 12458299 | 94.85 ns | 144 byte | 2 |
| Standard Library 언마샬 | 1562784 | 796.6 ns | 232 byte | 6 |
| Go-Json 언마샬 | 8492500 | 137.0 ns | 96 byte | 1 |
프로파일링 결과이다.
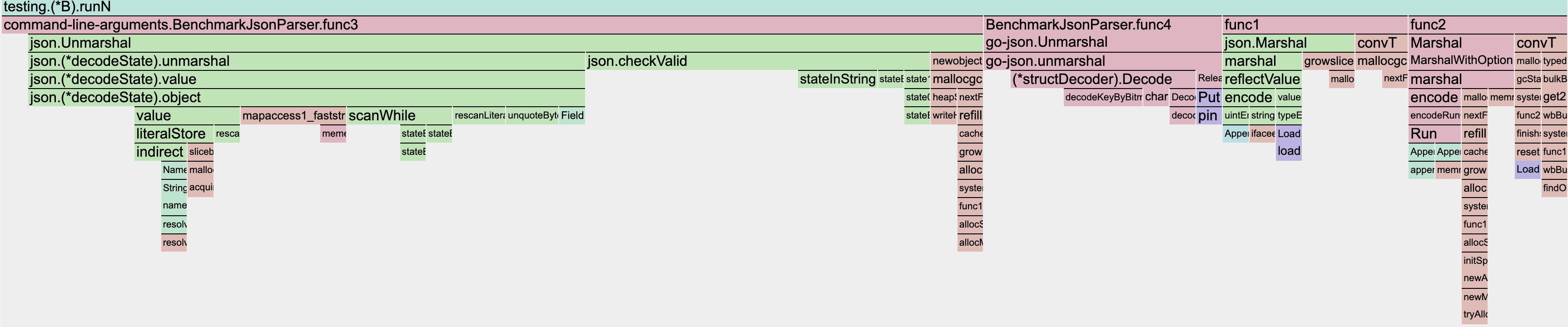
go-json이 빠른 이유는 reflect 코드의 제거와 buf의 재사용과 인터페이스 사용을 지양하여 최대한 스택 메모리 할당을 하는 방법으로 성능 개선을 했다.
'Go > Go Basic' 카테고리의 다른 글
| Env-Config (kelseyhightower/envconfig) (2) | 2023.10.16 |
|---|---|
| AES 암호화 적용 In Go (1) | 2023.10.10 |
| Ultimate-Go-06 [에러처리] (0) | 2023.09.19 |
| Ultimate-Go-04 [디커플링] (0) | 2023.09.13 |
| Ultimate-Go-03 (2) | 2023.09.07 |