프로젝트에서 중간중간 긴급하게 수정하고, 내가 부족한 부분이 많아 상당한 부분을 리팩터링 하는데 시간을 보내 개인적인 공부할 시간조차 할애하기 어려웠다. 변명은 그만하고 바로 가보자.
이번 챕터는 데이터 구조이다. 바로 가보자.
배열 Array
1-1. CPU 캐시
코어들은 메인 메모리에 바로 접근하지 않고, 로컬 캐시로 접근한다. 캐시의 속도는 L1, L2, L3 메모리 순으로 빠르고 "퍼포먼스"가 중요하다면 모두 캐시메모리에 접근해야 한다.
1-2. Cache miss
캐시 미스란 코어에서 처리하고자 하는 데이터가 캐시에 없는 상태를 말한다. 위의 CPU캐시에 없다면 메인 메모리까지 접근해야 하고 이는 성능상 캐시보다 많이 느린 성능을 제공하게 된다.
프로세스는 프래패쳐를 가지고 있는데 이는 어떤 데이터가 필요할지 예상하는 것을 말한다. 다시 말해 프리패쳐를 이용해 예측가능한 데이터 접근 패턴을 생성하는 코드를 작성하는 것 이것이 캐시미스를 줄이는 방법이다.
그래서 이 캐시 미스, CPU 캐시랑 Array와 도대체 무슨 관련이 있는가?라고 생각이 들 수 있다. 배열은 메모리의 연속할 등을 하게 된다. 다
시말해 배열로 할당하고 이를 순회한다면? 이는 캐시미스의 확률을 상당히 줄여주게 된다.
n*n의 큰 행렬이 있다고 할 때 이를 순회하기 위해
1. LinkedList 순회 : TLB 변환색인버퍼 페이지와 오프셋을 이용해 중간 성능을 가지게 된다.
2. 열 순회 : 열순회는 캐시 라인을 순회하지 않는다. 메모리 임의접근패턴을 가진다.
3. 행 순회 : 행순회는 캐시 라인을 순회하며 예측 가능한 접근패턴을 만든다.
성능의 우선순위를 구분하면? 3 > 1 > 2의 순서를 가진다.
1-3. TLB 변환 색인버퍼
캐싱 시스템은 하드웨어로 한 번에 64바이트(기계별로 다르다) 씩 데이터를 옮긴다. 운영 체제는 4k 바이트씩 페이징 함으로써 메모리를 관리한다.
관리되는 모든 페이지는 가상 메모리주소를 갖게 되는데, 올바른 페이지에 매핑되고 물리적 메모리로 오프셋 하기 위해 사용된다.
여기서 위에서 linkedList 가 중간 성능을 가지는 이유를 알 수 있다.
다수의 노드가 같은 페이지에 있기 때문이다.
그렇다면 왜 열순위가 마지막 순위에 도달하는가? 일반적으로 캐시미스, 변환색인버퍼 미스가 둘 다 발생할 수 있는 게 열 순회의 경우이다.
위의 1,2,3 모두 지향하는 바는 똑같다. 데이터 지향설계
효율적인 알고리즘에 그치지 않고, 어떻게 데이터에 접근하는 것이 알고리즘 보다 성능에 좋은 영향을 미칠지 고려하는 것
배열을 왜 써야 하는지 배열을 쓰면 어떻게 동작하는지에 대해 알아보았다. 실질적으로 코드에서 어떻게 작성하고 선언하는지에 대해 알아보자.
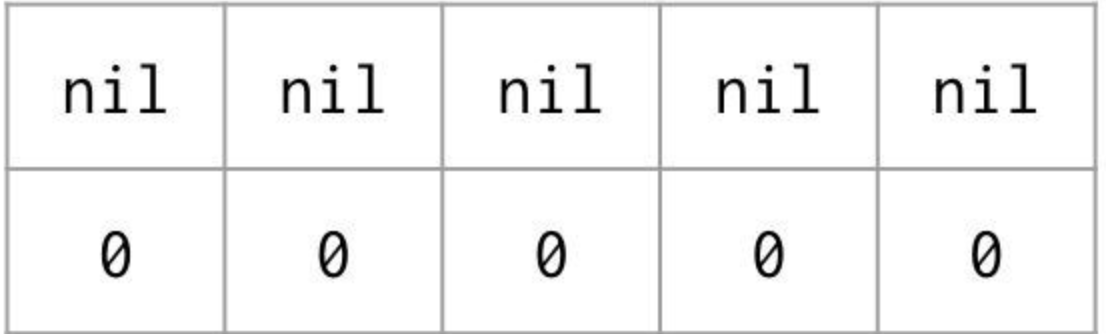
var string [5]string
위와 같이 선언하게 되면 각 배열은 위의 그림과 같은 형태의 제로값으로 설정된다. 문자열은? 포인터와 길이를 표현하는 2 단어로 표현되기 때문이다.
fmt.Printf("\n=> Iterate over array\n")
for i, fruit := range strings {
fmt.Println(i, fruit)
}
해당 코드블록과 같이
Println을 호출할 때 같은 배열을 공유하는 4개의 문자열을 가지게 되는 것이다. 문자열의 주소를 함수에 전달하지 않으면 이점이 있다. 문자열의 길이를 알고 있으니 스택에 둘 수 있고, 그 덕분에 힙에 할당하여 GC를 해야 하는 부담을 덜게 된다. 문자열은 값을 전달하여 스택에 둘 수 있게 디자인되어
이런 설명이 붙는데 한참 다시 읽어 봤다.
fruit는 string의 값을 하나씩 복사해서 선언된 메모리 주소에 계속 덮어 씌운다. Println 은 Go의 함수와 같이 파라미터로 전달된 값은? value 복사를 하게 된다. 그렇기 때문에 매번 함수가 호출될 때마다 매번 다른 fruit의 값을 프린트할 수 있게 되는 것이고,
힙에서는 공유되는 fruit에 대해서만 가비지컬렉팅이 발생되고, 프린트 함수에서는? 복사된 값을 가지기 때문에 해당 변수는 스택에 할당된다.
슬라이스
make([]string,5)
위의 코드를 실행하면 아래와 같은 이미지의 메모리 할당이 이뤄진다.
여기서 특이한 개념이 나오게 되는데 "길이와 용량이라는 개념이다."
make 함수를 이용해서 slice, map, channel을 생성할 수 있는데 여기서 3번째 키워드는 용량을 나타낸다.
길이는 포인터로부터 읽고 쓸 수 있는 수를 의미하지만, 용량은 포인터부터 배열에 존재할 수 있는 총량을 의미한다.
var data []string
data2 := []string{}
두 개는 다르다. data는 빈 슬라이스지만 nil 포인터를 갖고 있는 비어이 있는 슬라이스가 된다.
nil 슬라이스 와 비어있는 슬라이스는 각기 다른 의미를 가진다. 제로값으로 설정된 참조 타입은 nil로 여길수 있다는 점이다. marshal에 이 nil과 비어있는 슬라이스를 넘긴다면 json에서는 null과 [] 있는 각각의 슬라이스를 반환하게 된다.
append 함수의 특징상 capacity에 다다르면 새로운 메모리 주소를 할당한다.
func Test_SliceReference(t *testing.T) {
x := make([]int, 7)
for i := 0; i < len(x); i++ {
x[i] = i * 100
}
twoHundred := &x[1]
x = append(x, 800)
x[1]++
fmt.Println(x[1], *twoHundred)
}
twoHundred와, x [1]은 다른 메모리 주소를 가진다. append를 사용해 7 이 넘은 슬라이스의 상태가 되어 새로운 메모리 주소가 할당된다.
UTF8의 경우 지난번 string에 대해서 언급한 것 string을 range로 조회할 때 단어 하나단위로 조회된다고 작성했다.
프로젝트를 하면 할수록, 내가 명확하게 무엇을 아는가? 에 대해서 고민하게 되었고. Ultimate Go라는 글을 읽어보고자 한다.
사실 Go Slack에서 물어보니 이거랑, Go in Action을 추천해 주더라 먼저 Ultimate Go를 읽어보자.
문법
- 지금 와서 생각해 보면 바이트, 비트의 개념이 생각보다 많이 없지 않았나 싶다.
1바이트 => 8비트이다. 그렇다면 +- 부호비트를 제외하고 7자리 최댓값은 2의 7승 127까지 표현된다. 특히나 고에서는 이러한 표현에 있어 그냥 넘어가는 게 아닌 기민하게 받아들여야 한다.
생성되는 모든 변수는 초기화되어야 한다. 어떤 값으로 초기화할지 명시하지 않는다면, 제로값으로 초기화된다. 할당된 메모리의 모든 비트는 0으로 리셋된다.
- 사실 저 부분 4번 읽어봤다. 이해한 바에 따르면 언어의 변수를 생성하고 값을 명시하지 않는다. 예를 들어
var a int64라고 가정한다면 이는 8바이트짜리 메모리 공간을 할당한다.
즉 메모리의 시작주소와 크기가 정해져 있지만 값을 할당하지 않아 8바이트 의 모든 비트는 00000000..... 0000으로 표기된다는 의미이다.
문자열은 uint8 타입의 연속이다.
- 문자열 가지고 for 문 돌려보면 rune 타입으로 반한 된다, 여기서 rune 은 int32의 alias 별칭타입이다 그냥 숫자 덩어리이다.
그러면 의문이 생긴다. uint8과 rune 은 엄연히 다른 타입 즉 메모리 사이즈 가 다르다. 왜 다를까?
1. 문자열 : uint8 타입의 연속이고 이는 UTF8 인코딩 된 문자를 나타낸다.
2. rune : unit32의 별칭이고, 주로 Unicode 코드포인트를 표현하는 데 사용된다.
다시 말하자면 utf8 인코딩 은 다양한 길이의 바이트 시퀀스를 이용해 유니코드 문자를 나타낸다.
어떤 문자는 1바이트, 어떤 문자는 2,3,4 바이트로 나타내야 할 수도 있다. 그렇기 때문에 for 문을 이용해서 range 처리를 하게 되면
uint8로 표현을 하게 되면 올바르게 utf-8 을표현할 수가 없다. 따라서 rune을 이용해 반환하게 된다.
유니코드 : 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업표준으로 코드포인트가 존재한다. 예를 들어 ) ㅇ : U+3147 , 안 UTF-8 : 유니코드를 바이트 시퀀스로 인코딩하는 방식이다.
func Test_String_Rune(t *testing.T){
a := "안녕"
}
위와 같이 a라는 값이 할당되면 우리의 명석한 고 컴파일러 님은
1. 안과 녕 에 해당하는 유니코드 포인트로 해석을 하고
2. 해석된 값을 UTF-8로 인코딩을 하고 (한글은 3바이트) 총 6바이트 길이의 배열이 필요하고 이에 메모리 할당을 하고
3. 문자열 a는 해당된 문자열 바이트 의 주소 시작값을 가지고, 6이라는 사이즈의 길이를 가진다.
이렇게 되면 len(a) 문자열의 길이를 추출하게 될 때 이는 6이라는 숫자를 반환한다.
실제 "안녕"에 대해 추출하고 싶을 때 rune을 이용하게 된다.
다시 말해
a의 길이를 뽑으면 6이 될 것이고, rune 으로 변환해서 조회한다면 2라는 크기가 나온다.
for 루프를 이용해서 a를 조회하면 총 6번의 값을 조회해서 나타내주고, for... range를 이용해서 조회하면 유니코드 기준으로 조회되어 2번의 값을 조회해서 나타내준다.
for loop의 바이트 시퀀스 조회하는 것의 복잡성을 숨기고자 for... range는 문자열을 더 자연스럽게 순회가 가능하다.
func Test_Variable_String_Rune(t *testing.T) {
a := "안녕"
for i := range a {
fmt.Printf("%v ", a[i])
}
fmt.Println("------------------")
for i := 0; i < len(a); i++ {
fmt.Printf("%v ", a[i])
}
fmt.Println()
}
그렇다면 for loop 의 바이트를 문자열로 조회하고자 한다면?
func Test_Variable_String_Rune(t *testing.T) {
a := "안녕"
for i := 0; i < len(a); {
r, size := utf8.DecodeRuneInString(a[i:])
fmt.Printf("%d\t%c\n", i, r)
i += size
}
}
이렇게 조회를 하게 되면 "안", "녕"으로 조회가 가능하다. 해당 함수 utf8.DecodeRuneInString(s string)를 살펴보면
내부적으로 단순하게 주어진 s에 대해서 0~3까지 총 4개의 자리에 대해서 탐색을 한다. 즉 4바이트 탐색을 실시하고,
그거에 맞춰 rune과 크기 값을 반환한다. 각 바이트 별 검사하는 로직은 비트연산과 미리 정해놓은 상수값들을 이용해 비교하고 반환을 해주는데 생각보다 코드가 어지럽지만 해당 함수가 어떻게 검사하고 반환하는지에 대해 살펴보았다.
구조체 선언과 구조체 패딩
- 구조체에 할당된 메모리에는 메모리 패딩이라는 것이 존재한다.
func Test_Memeory_Address(t *testing.T) {
type ex struct {
counter int64
pi float32
flag bool
}
type ex2 struct {
flag bool
counter int64
pi float32
}
var e ex
var e2 ex2
fmt.Println(unsafe.Sizeof(e), unsafe.Sizeof(e2))
}
해당 테스트의 결괏값으로 e는 16 e2는 24의 메모리 사이즈를 가져간다 왜 동일한 구조체에 서로 다른 메모리 사이즈일까? 고 언어 에는 메모리패딩을 주어 cpu 가 각 경계별로 손쉽게 읽을 수 있도록 해주고 있다.
ex1의 경우 8바이트(counter) + 4바이트(pi) + 패딩 3바이트 + 1바이트(flag) => 이렇게 총 16바이트가 된다.
ex2의 경우 1바이트(flag) + 7바이트(패딩) + 8바이트(counter) + 4바이트(pi)+4바이트(구조체패딩) => 이렇게 24바이트가 된다.
구조체 패딩은 구조체 내에 가장 큰 바이트 기준의 배수로 구조체가 정렬되어야 하기 때문에 4바이트의 추가 패딩이 붙는다.
구조체의 패딩을 제외한다면 실제 구조체의 패딩에 각각 3,7 바이트의 차이가 존재한다.
구조체를 뭐 어마무시하게 많은 필드를 넣어서 생성하지는 않겠지만 이러한 규칙이 있어 메모리의 효율적인 사용을 위한다면 가장 큰 메모리를 앞단에 위치시켜야 한다는 사시을 알아야 한다.
포인터 항상 값을 전달한다
- 함수는 함수자체적으로 스택프레임을 가진다. 즉 함수 내에서 사용되고자 하는 값들에 대해 스택프레임에 위치해 해당 함수를 호출하면 모두 제로값으로 초기화되고 함수가 종료되면 스택 은알아서 정리가 된다. 이에 따라 다른 함수에서 해당 값에 접근을 할 수가 없다.
이에 값의 공유 고 루틴(고 루틴 또한 일반적으로 2K 스택메모리를 가지게 된다.) 이러한 고 루틴의 스택들 간에 값을 공유하기 위해서는?
포인터라는 값을 공유해야 한다.
func stayOnStack() user {
u := user{
name: "Ho",
email: "email",
}
return u
}
func escapeToHeap() *user {
u := user{
name: "Ho",
email: "email",
}
return &u
}
해당 함수들을 보면 stayOnStack의 경우 해당 값을 반환함과 동시에 함수 내의 u는 스택에 적재되어 있다가 한 번에 같이 사라지게 된다.
반면 esacpeToHeap을 보면 u의 주소값은 함수 밖을 나와 메모리의 값이 반환되어 스택이 아닌 힙에 적재된다.
이를 go에서는 이스케이프 분석이라고 하며, 변수의 생명주기를 컴파일러가 스택에 넣을지 힙에넣을지 여부를 판단하여 할당하는 것을 의미한다.
func Test_Pointer_Address(t *testing.T) {
fmt.Println(stayOnStack())
fmt.Println(escapeToHeap())
// go test -gcflags '-m -l' advance/variable_test.go
}
go test -gcflags=' -m -l' variable_test.go
위에 테스트를 제시된 코드로 실행하게 되면 아래와 같은 결과를 받을 수 있다.
./variable_test.go:61:25: stayOnStack() escapes to heap ./variable_test.go:62:13:... argument does not escape
음? stayOnStack() 은 heap으로 빠지면 안 된다 왜 빠진 거고, 포인터를 반환하는 escapeToHeap 은 왜 이스케이프 되지 않았는가? fmt.Println()의 함수 인자값으로 넘길 때 해당 인자를 힙으로 이스케이프 되었고, escapeToHeap의 경우는 이미 힙으로 이스케이프 되어있기 때문에 할 필요가 없어 위와 같은 메시지를 받게 되는 것이다.
최근 디자인 패턴을 공부하면서 Interface, Type에 대해 부족한 부분을 발견하고 이번 기회에 쉬는 날 정리해 보고자. 글을 작성한다.
GO TOUR 에서 작성된 글에 의하면?
인터페이스 타입 은 특정 함수를 정의 하는 용도로 사용한다. Java에 익숙한 사람들이라면 아래 예제는 당연하고 이해가 간다.
type Sender interface {
send()
}
type Bank struct {
account Account
}
func (b *Bank) send() {
fmt.Printf("%v 에서 돈을 보냅니다 .", b.account.ID)
}
type Account struct {
ID string
Balance uint
}
func main() {
var a Sender = &Bank{Account{"귀우 의 계좌", 123}}
a.send()
}
Sender 인터페이스 를 선언 (er을 이용해 Interface를 정의한다 "GO effecitve")
뱅크의 타입을 선언 했지만? Sender의 타입으로 받아서 샌더가 가지고 있는 함수를 사용할 수 있다.
당연하다 그렇다면 역으로도 가능한가 ? 저 특정 인터페이스에서 원하는 타입을 뽑아야 내하는 경우가 생긴다면 어떻게 할 것인가?
가능하다. 어떻게 ?
bank := &Bank{Account{"귀우 의 계좌", 123}}
var a Sender = bank
a.send()
if x, ok := a.(*Bank); ok {
x.send()
}
Interface로 선언된 타입은 최초 구현은 Bank의 포인터 타입이다.
추출하고자 하는 정확한 타입에 대해 위와 같이 추출해서 사용한다.
좋다 인터페이스 와 구현하는 구조체 간의 쌍방향 관계가 된다 는 사실을 알았으니 이제 타입 끼리 해보자.
동일한 인터페이스를 구현하는 2개 의 타입 간의 크로스 캐스팅이 가능한가?
type Email struct {
sender string
receiver string
address string
}
func (e *Email) send() {
fmt.Printf("%v 에서 %v 읭 %v 로 보냅니다. ", e.sender, e.receiver, e.address)
}
func main() {
var a Sender = email
if v, ok := a.(*Email); ok {
v.send()
}
if v, ok := a.(*Bank); ok {
v.send()
}
}
이 경우 콘솔에서는 메일에 해당하는 샌더를 실행시켜 준다. 즉 2번째 if 문이 false로 타입추출에 실패했다.
그래서 이게 뭐? 당연한 거 아닌가?
아래 예제를 보자.
type ExpressEmail struct {
*Email
price int
}
func main() {
//bank := &Bank{Account{"귀우 의 계좌", 123}}
email := &ExpressEmail{
&Email{"a", "b", "13472 Mortgatan6 Saltjobaden"},
10000000,
}
var a Sender = email
fmt.Println(reflect.TypeOf(a))
if v, ok := a.(*Email); ok {
v.send()
}
if v, ok := a.(*ExpressEmail); ok {
v.superFast()
v.send()
}
}
ExpressEmail로 인터페이스를 받아서 Email을 뽑으려고 하면 실패한다. 왜? ExpresEmail 구현체 안의 Email 도 하나의 고유한 타입이기 때문에 위와 같이 타입 추출이 불가능하다. (반면 자바는 가능하다.)
여기서 언어의 차이가 드러난다. 객체 지향과, 그렇지 않은 그래서 클래스의 상속에 따른 구조와 임베디드 타입에 의한 새로운 타입의 차이 가 있기 때문에 위와 같은 동일한 로직에서 서로 다른 결과를 얻게 된다.
반면 인터페이스 안에 인터페이스로 정의된다면 그건 타입캐스팅이 될까?
type Sender interface {
send()
}
type Receiver interface {
receive()
}
type SendReceive interface {
Sender
Receiver
}
type CommonSendReceive struct{}
func (c *CommonSendReceive) send() {
fmt.Println("Send Common Message")
}
func (c *CommonSendReceive) receive() {
fmt.Println("Receive Common Message")
}
func main() {
var sr SendReceive = &CommonSendReceive{}
if v, ok := sr.(Sender); ok {
v.send()
}
if v, ok := sr.(Receiver); ok {
v.receive()
}
}
놀랍게도 가능하다. 인터페이스 안에 임베디드 타입으로 구성된 인터페이스에 대해서는 타입 추출이 가능해진다.
왜 그럴까?
타입 추출은 컴파일러에게 인터페이스를 구현하는 것으로부터 내가 원하는 것처럼 뽑아달라고 부탁하는 것이다.
이렇게 되면 인터페이스 값에 기반하지 않은 타입이라면 에러가 발생하게 된다.
그러나 인터페이스 유니온 즉 인터페이스끼리 결합된 인터페이스에서는 분리가 가능해진다.
인터페이스의 결합을 코드로 풀면? 그냥 두 개의 메서드 합친 결과물이다. 그러니 당연히 필요한 부분의 분리가 가능해진다.
왜? 정확히는 컴파일러에게 내가 원하는 메서드를 어떤 걸 사용할 건데 그 타입으로 뽑아줘라고 부탁을 하는 것이기 때문이다.
아까 예제 ExpressEmail에서 email을 뽑아보자.
type Sender interface {
send()
}
type Email interface {
sendEmail()
}
type email struct{}
func (e *email) sendEmail() {
fmt.Println("고유 이메일")
}
type ExpressEmail struct {
Email
price int
}
func (e *ExpressEmail) send() {
fmt.Println("Send Express Email")
}
아까 와의 차이가 무엇인가? 인터페이스 타입을 인자로 가지냐 아니면 특정 타입이냐의 차이가 되고 그 결과는 타입 추출 의 가능 여부를 판별한다.
func main() {
var a Sender = &ExpressEmail{
&email{},
500,
}
if v, ok := a.(*ExpressEmail); ok {
v.send()
}
if v, ok := a.(Email); ok {
v.sendEmail()
}
}
위와 같은 코드는 전부 실행이 된다. 인터페이스의 강력함이 아닐수가 없다...
심지어 인터페이스가 아닌 구조체를 넣게 되더라도 그게 특정 인터페이스를 구현하고 있다면 인터페이스 의 타입추출이 가능해진다.
func main() {
var a Sender = &ExpressEmail{
email{},
500,
}
if v, ok := a.(*ExpressEmail); ok {
v.send()
}
if v, ok := a.(Email); ok {
v.sendEmail()
fmt.Println(reflect.TypeOf(v))
if e, ok := v.(*email); ok {
fmt.Println(reflect.TypeOf(e))
}
}
}
이 코드에서 보면 email이라는 구조체는 Email 인터페이스를 구현하고 있고 우리는 그 안에 email 있다는 사실을 알고 역으로 풀고자 한다.
그러나 마지막 if 문에서 프린트 라인이 찍히지 않는다. 왜?
reflect를 이용해 타입 추출을 하더라도 저 타입은 아직도 ExpressEmail이다. 즉 cpu는 이렇게 알고 있다는 소리이다.
아무리 우리가 밖에서 Email로 추론하고 값을 달라고 하더라도 cpu에서 지정된 오리지널 값에서 잘라서 준다는 의미이다.
아무래도 고에서 지원하는 상속과 embedded 타입 간의 간극을 잘 파악하여 사용하지 않는다면 오류를 남발하는 코드를 작성할 것이다.
드디어 고 언어의 꽃인 동시성 프로그래밍 챕터에 왔다. 지나오면서 고 언어에서 oop 를 하기위해 제공되는 여러 키워드 들을 살펴봤고 문법 과 실행 방식에 대해 공부했지만 이번에는 그 결이 다른 동시성 프로그래밍 이다.
바로 읽어보자.
Share by communicating
고 에서는 공유된 자원이 채널 을 통해 전달되는 기존 동시성 프로그래밍 의 방법과 궤를 달리한다고 한다.
오직 하나의 고루틴 에서만 주어진 시간 동안 값에 접근 할수있다. 이에 따른 데이터 레이스는 설계에 따라 발생할수 없다.
왜 ? 데이터 레이스란 하나의 값에 동시다발적으로 두개 혹은 그이상의 동시쓰레드 가 접근하려고 할때 발생 되는데 현재 문서에서 말하는 오직 하나의 고루틴에서만 접근하기 때문에 설계적으로 발생할수 없다고 한다.
고 에서 는 변수 주변에 뮤텍스 락을 걸어 수행할수 있다 다만 채널 을 사용해 접근한다면 ? 보다 명확하고 올바르게 프로그램을 더 쉽게 작성할수 있다.
Goroutines
기존 용어의 다양한 전달에 따라 고루틴으로 부르고 있다. 고루틴은 단순한 모델을 가지고 잇는데. 동일한 주소 공간을 가지고 함수 와 고루틴 이 동시실행되는 것을 의미한다.
고루틴 은 가벼우며, 스택 에 할당되는 값보다 조금 더 비용이 소모된다. 스택 은 메모리 할당 의 비용이 저렴하며, 많은 할당 즉 데이터가 요구 되어진다면, 힙메모리를 이용하기도 한다.
응 ? 문장이 매우 난해하다. 기본적으로 이 베이스가 있어야 한다. 스택 > 힙 메모리 공간 보다 빠르다. 그러나 힙 처럼 다량 을 한번에 할당하기에 제한이 있다. 그렇기에 고루틴은 경량 쓰레드 라는 별명이 있다 왜 ? 스택에 할당되기에 가벼워야하며 빠르기때문에 (스택 은 Cpu 단일 메모리 로 접근이 가능하기에 빠르다 주로 함수호출, 함수 반환값 주소, 임시변수 등이 할당됨)
글을 마저 읽다보면 The effect is similar to the Unix shell's¬ation for running a command in the background 유닉스 쉘의 & 백그라운드 실행과 유사한 기능을 한다고 한다.
예시를 보자.
func Announce(message string, delay time.Duration) {
go func() {
time.Sleep(delay)
fmt.Println(message)
}() // Note the parentheses - must call the function.
}
우선 저 함수 선언 과 호출 부분 부터 눈에 가장 확실히 들어오는데 go 키워드를 앞에붙여주며 함수를 선언과 동시에 실행한다.
이건 Go 루틴의 일반적인 예시가 아니라고 한다 왜 ? 완료 신호를 보내줄수 없기 떄문에 이 고루틴 함수가 언제 끝나는지 모른다.
이에 따라 채널을 활용한 방법에 대해 이야기 하는데 예제 몇개를 더 작성해보면서 연습해보자.
func main() {
practice.F("Direct")
go practice.F("GoRoutine")
go func(msg string) {
for i := 0; i < 3; i++ {
fmt.Println(msg, ":", i)
}
}("anonymous")
time.Sleep(time.Second)
fmt.Println("Done")
}
Direct : 0
Direct : 1
Direct : 2
anonymous : 0
anonymous : 1
anonymous : 2
GoRoutine : 0
GoRoutine : 1
GoRoutine : 2
Done
이런 결과 값이 나온다. 그러나 여러번 실행하면 멀티쓰레드 답게 순서 보장없이 마구잡이로 나온다.
단 중간에 타임 슬립 이 있다 이게 왜 필요할까 ?
메인 펑션 또한 고루틴 함수이다. 이에 메인 펑션은 종료되면 ? 모든함수가 종료된다. 즉 저 고루틴 이 실행되는것을 기다려주지 않는다.
만약 저 중간 함수가 없다면 ? 메인 고루틴은 코드를 쭉읽어가면서 함수를 바로 종료한다.
그래서 이 위의 설명중 하나 완료신호 를 주는 방법 중 하나로 채널에 대해 언급하는 이유이다.
(이렇게 말고 sync.WaitGroup 을 이용해 저렇게 슬립을 안하고 이용하는 방법도 있다)
Channels
전에 make 함수를 이용해서 만들수 있는 타입 중에 채널이 언급된 적이있다. 즉 채널을 생성하기 위해서는 make 함수를 이용해 만들고 이에 대한 반환값은 ? 값벨류 이지만 값복사 가 아닌 레퍼런스 복사가 발생한다.
또한 채널의 버퍼사이즈를 설정해줄수 있다. 마치 슬라이스 사이즈를 설정하는것과 유사하다.
ci := make(chan int) // unbuffered channel of integers
cj := make(chan int, 0) // unbuffered channel of integers
cs := make(chan *os.File, 100) // buffered channel of pointers to Files
func main() {
c := make(chan int)
go func() {
fmt.Println("Go routine is Running")
for i := 0; i < 10; i++ {
c <- i * i
}
}()
for i := 0; i < 10; i++ {
fmt.Println("Value is : ", <-c)
}
fmt.Println("Function is done")
}
채널 에 데이터 를 집어넣고 그 갯수 만큼 뺴는 로직이다. 재미있는 부분이 있는데 <-c 채널에서 이렇게 데이터를 뽑는 부분에서 넣어주는 데이터 와 끝나는 데이터 가 일치하지 않으면 ? 채널을 받는 로직에서는 무한히 기다리면서 메인 고루틴 과의 데드락 을 야기한다.
언퍼버 채널 이라면 ? 송신자는 수신자가 데이터를 수신할떄 까지 기다리고, 수신자는 송신자가 데이터를 전달해줄때 까지 기다린다.
버퍼 채널 이라면 ? 송신자는 버퍼의 사이즈가 가득차기 전까지 계속 데이터를 보낸다. 만약 가득찼다면 수신자 중가 데이터를 원복할떄 까지 기다린이후 다시 재 진행 된다. 아래 예를 보자.
func main() {
// Buffered channel with buffer size 2
bufferedChannel := make(chan int, 5)
go func() {
for i := 1; i <= 5; i++ {
bufferedChannel <- i
fmt.Println("Sent value on buffered channel:", i)
}
close(bufferedChannel)
}()
for value := range bufferedChannel {
fmt.Println("Received value from buffered channel:", value)
}
fmt.Println("Buffered channel is done.")
// Unbuffered channel
unbufferedChannel := make(chan int)
go func() {
for i := 1; i <= 5; i++ {
unbufferedChannel <- i
fmt.Println("Sent value on unbuffered channel:", i)
}
close(unbufferedChannel)
}()
for value := range unbufferedChannel {
fmt.Println("Received value from unbuffered channel:", value)
}
fmt.Println("Unbuffered channel is done.")
}
Sent value on buffered channel: 1
Sent value on buffered channel: 2
Sent value on buffered channel: 3
Sent value on buffered channel: 4
Sent value on buffered channel: 5
Received value from buffered channel: 1
Received value from buffered channel: 2
Received value from buffered channel: 3
Received value from buffered channel: 4
Received value from buffered channel: 5
Buffered channel is done.
Sent value on unbuffered channel: 1
Received value from unbuffered channel: 1
Received value from unbuffered channel: 2
Sent value on unbuffered channel: 2
Sent value on unbuffered channel: 3
Received value from unbuffered channel: 3
Received value from unbuffered channel: 4
Sent value on unbuffered channel: 4
Sent value on unbuffered channel: 5
Received value from unbuffered channel: 5
Unbuffered channel is done.
보는 바와 같이 버퍼 와 언버퍼 간의 차이가 존재한다. 따라서 이런 두종류 의 버퍼에 대해서 선택할떄 여러가지 경우의수를 고려해야할것으로 보인다. 만약 리시버가 느리다면 ? 버퍼 채널이라면 ? 샌더는 자주 락에 걸려 성능저하 가 발생하고 메모리 의 사용 제한이 생긴다면 ? 버퍼 채널인 경우 적절한 사이즈 를 찾는데 있어 고심을 해야한다.
Channels of channels
이러한 채널 또한 타입으로 인정받고 넘길수 있다.
이전 예제로 서버에서 리퀘스트 를 유니크하게 유지하는 방법에 대한 예제를 들었는데
거기서 Request 의 타입에 대한 정의를 내리진 않았다.
type Request struct {
args []int
f func([]int) int
resultChan chan int
}
func sum(a []int) (s int) {
for _, v := range a {
s += v
}
return
}
request := &Request{[]int{3, 4, 5}, sum, make(chan int)}
// Send request
clientRequests <- request
// Wait for response.
fmt.Printf("answer: %d\n", <-request.resultChan)
클라이언트 는 위와 같은 함수를 제공하고 채널로 데이터를 보내주면 ?
func handle(queue chan *Request) {
for req := range queue {
req.resultChan <- req.f(req.args)
}
}
서버에서는 단순 리퀘스트 안 채널로 받은 함수의 결과값을 받아 넣어주면 된다.
Parallelization
채널 사용의 병렬화 이다. 어떻게 ? 멀티 코어에 각 계산의 조각 을 주고 실행하는것이다. 바로 가보자.
아이템 의 백터를 하는데 있어 비용이 많이들고, 각 값에 대해 모든 아이템은 독립적으로 수행된다고 해보자.
type Vector []float64
// Apply the operation to v[i], v[i+1] ... up to v[n-1].
func (v Vector) DoSome(i, n int, u Vector, c chan int) {
for ; i < n; i++ {
v[i] += u.Op(v[i])
}
c <- 1 // signal that this piece is done
}
그래서 우리는 총 실행되는 숫자의 갯수만 신경쓰면된다.
const numCPU = 4 // number of CPU cores
func (v Vector) DoAll(u Vector) {
c := make(chan int, numCPU) // Buffering optional but sensible.
for i := 0; i < numCPU; i++ {
go v.DoSome(i*len(v)/numCPU, (i+1)*len(v)/numCPU, u, c)
}
// Drain the channel.
for i := 0; i < numCPU; i++ {
<-c // wait for one task to complete
}
// All done.
}
여기서 강조하는 문구로는 동시성 과 병렬성을 혼동하지말라고 한다.
고는 동시성 언어이지, 병렬성을 위한 언어가 아니다. 그럼에도 불구하고 종종 구조 적 인 방법으로 병렬성 문제를 쉽게 해결할수 있지만. 고는 동시성 언어 이다. 모든 병렬적 문제를 해결하기 위해 알맞지 않을수도 있다. 라고 한다.
* 아침을 한다고 가정
동시성 => 계란을굽는다(), 식빵을 굽느다(),커피머신을 돌린다()
병렬성 => 팬(계란을 굽는다(), 베이컨을 굽는다())
로 분리할수 있다.
A leaky buffer
줄줄 새는 버퍼 라는 즉 관리되지 않는 버퍼 라는 타이틀이다.
var freeList = make(chan *Buffer, 100)
var serverChan = make(chan *Buffer)
func client() {
for {
var b *Buffer
// Grab a buffer if available; allocate if not.
select {
case b = <-freeList:
// Got one; nothing more to do.
default:
// None free, so allocate a new one.
b = new(Buffer)
}
load(b) // Read next message from the net.
serverChan <- b // Send to server.
}
}
고루틴 클라이언트 가 데이터 를 소스로 부터 반복적으로 받는다고 가정해보자 . 버퍼 하나를 잡고 리스트 로 부터 데이터를 잡아 넣어주고 준비가 되었다면 ? 서버채널 로 이 버퍼를 날려준다.
func server() {
for {
b := <-serverChan // Wait for work.
process(b)
// Reuse buffer if there's room.
select {
case freeList <- b:
// Buffer on free list; nothing more to do.
default:
// Free list full, just carry on.
}
}
}
서버 는 서버 채널로 부터 데이터를 가져와서 특정 로직을 거치고 그 채널에 메모리가 남아있다면 다시 리스트로 보내는 로직이다.
만약 freeList 가 가득차있다면 ? 현재 가져온 버퍼는 가비지 컬렉터의 수집대상이 된다.
이 패턴은 오브젝트를 다시 사용하는 단순한 패턴이다. 메모리 할당의 오버헤드 를 줄이기 위해 사용되는 방법중 하나라고 한다.
Go 언어를 공부하면서 제일 고민이 많이 되었던 부분이다. 어떤 예제는 메서드로 어떤 예제는 그냥 함수로 설정해 리턴한다.
두 가지 방법을 모두 확인해 보자.
type ByteSlice []byte
func (slice ByteSlice) Append(data []byte) []byte {
// Body exactly the same as the Append function defined above.
}
func (p *ByteSlice) Append(data []byte) {
slice := *p
// Body as above, without the return.
*p = slice
}
둘 다 동일한 로직이다. 다만 표현의 차이인데 이에 대해 규칙을 아래와 같이 설명하고 있다.
1. 두 번째 함수는 포인터 그리고 값 모두에서 작동되지만, 값 메서드는 오직 값 타입에서만 함수를 호출할 수 있다 는 차이점이다. ChatGpt 가 준 예시를 보자.
type MyInt int
func (m MyInt) add(x int) MyInt {
return m + MyInt(x)
}
func (m *MyInt) addPointer(x int) MyInt {
*m += MyInt(x)
return *m
}
a := MyInt(5)
b := &a
// Value method can be invoked on a value
fmt.Println(a.add(10)) // 15
// Value method can also be invoked on a pointer
fmt.Println(b.add(10)) // 15
// Pointer method can only be invoked on a pointer
fmt.Println(b.addPointer(10)) // 25
// Pointer method cannot be invoked on a value
// This will result in a compile error: "cannot call pointer method on MyInt value"
// fmt.Println(a.addPointer(10))
여기서 주목할 점은 a , b의 타입이다 a는 값타입 이고, b 는 포인터 타입이다. b 는 값,포인트 메서드 각각을 호출 가능하지만
a 는 포인터 메서드 호출 시에 에러가 발생한다.
이러한 규칙에 따라 포인터메서드는 호출 값을 수정할 수 있다는 점 과 값메서드는 호출 시 새로운 값을 받는 차이점 이 존재한다.
하나 고에서는 편리한 예외를 적용해 주는데 주소를 지정할 수 있는 변수라면 포인터 타입의 메서드 또한 호출할 수 있다는 점이다.
Okay thanks i see However in view of case on Effective go documentation they said "When the value is addressable, the language takes care of the common case of invoking a pointer method on a value by inserting the address operator automatically. In our example, the variable b is addressable, so we can call its Write method with just b.Write." if this is right your example is wrong, you would be able to call a.addPointer(10) as well.
Would you give me some more details?
Answer is :
Yes, I apologize for that mistake. You're correct, in Go, when the value is addressable (i.e., it has an address), you can call a pointer method on that value and Go will automatically insert the address operator.
In the example from the Effective Go documentation, b is a pointer to an addressable value, so you can call its Write method as b.Write. When you call a pointer method on a value, Go will automatically insert the address operator and convert the value to a pointer.
So, in our example, you could also call a.addPointer(10), and Go would automatically convert the value a to a pointer and call the addPointer method on that pointer. Here's an updated example to show this:
goCopy code
a := MyInt(5) b := &a // Value method can be invoked on a value fmt.Println(a.add(10)) // 15// Value method can also be invoked on a pointer fmt.Println(b.add(10)) // 15// Pointer method can be invoked on a pointer fmt.Println(b.addPointer(10)) // 25// Pointer method can also be invoked on a value fmt.Println(a.addPointer(10)) // 30
In this example, you can see that both b.addPointer(10) and a.addPointer(10) produce the same result.
잘못된 예시에 대해 사과를 해주는 게 정말 친절하다 ㅋㅋ 다만 나의 궁금증 은 해결되지 않았다. 어떤 상황에 대해 어떤 메서드를 써야 할지 에 대한 특별한 룰이나 나만의 기준을 정하고 싶어 추가적으로 좀 더 자료를 찾아보았다.
대체적으로 값은 변경을 원한다면 포인터 리시버를 그게 아니라면 벨류 리시버 를 사용한다고 한다. 추가적으로 포인터 리시버에 대한 고려사항으로 리시버 자체 의 크기가 너무 크다면? 이건 고려 의 여지없이 포인터 리시버를 사용해야 메모리 이슈가 없을 것이다. 팀장님 께 여쭤보니 글로벌한 함수에 대해서는 벨류를 보편적으로 사용하는 편이며 일관적으로 사용하는 것을 주로 한다고 하신다.
Interfaces and other types
Interfaces
인터페이스이다 자바에서 도 많이 보던 친숙한 키워드인데 고에서 는 어떻게 정의하는지 확인해 보자. 객체의 특정 행동 규약을 정의할 때 제공한다고 한다.
주로 1~2 개의 메서드를 정의하고, io.Writer의 Write를 예시로 들 수 있다.
(포스팅 은 안 했지만 주로 인터페이스 이름 규약으로는 뒤에 er을 붙인다.)
자바와 똑같이 하나의 타입은 다양한 인터페이스를 구현할 수 있다. 컬렉션 은 정렬될 수 있는데 sort의 구현체를 구현해야 한다.
Len() Less(i, j int) bool Swap(i, j int) 바로 예시를 들어 정렬을 해보자.
type twitter struct {
like int
title string
}
type twit []twitter
func (t twit) Len() int {
return len(t)
}
func (t twit) Less(i, j int) bool {
return t[i].like < t[j].like
}
func (t twit) Swap(i, j int) {
t[i], t[j] = t[j], t[i]
}
func main() {
a := twit{}
a = append(a,
twitter{249249, "Hi"},
twitter{123123, "Elon"},
twitter{1, "Musk"},
twitter{-1, "Paid for twit"},
)
fmt.Println(a)
sort.Sort(a)
fmt.Println(a)
}
[{249249 Hi} {123123 Elon} {1 Musk} {-1 Paid for twit}]
[{-1 Paid for twit} {1 Musk} {123123 Elon} {249249 Hi}]
프린트된 값을 보면 정렬된 것이 보이는가? 저기서 레스 함수를 반대로 꺾어준다면 역으로 정렬된다.
나름 직관적이라고 생각한다. 자바의 Comparable or Compartor 보다 마음에 든다.
Conversions
type Sequence [] int와 변환에 대해 설명하고 있다.
이 부분에서는 자바 인터페이스 Map a = HashMap <> 이런 식의 연관관계 가 생각난다. Map을 구현하고 있는 hashmap에 대해 타입으로 받을 수 있다?
Go에서는 위와 유사하게 형변환이 가능하다. 그래서 예제에서 들어준 sort에 대해 sequence의 len less 기타 등등 구현 없이 바로 가는 거를 보여준다.
type Sequence []int
// Method for printing - sorts the elements before printing
func (s Sequence) String() string {
s = s.Copy()
sort.IntSlice(s).Sort()
return fmt.Sprint([]int(s))
}
ㅋㅋㅋㅋ 별다른 구현 없이 이렇게 형변환 해서 들고 갈 수 있다.
저 함수 안으로 들어가면 이미 빌트인으로 다구현되어 있다 , 인트에 대해서
기존 함수 예제에서 String으로 리턴하기 위해 for를 한 번 더 돌리면서 sprint를 해 O(n) 2의 시간복잡도를 가지며 string을 만들어 갔지만 위와 같이 작성한다면?
o(nlogn)까지 줄어들 수 있다. s의 크기만큼 함수를 돌면서 정렬(고에서는 퀵정렬을 사용) 하기 때문에 o(nlogn) 이 된다.
Interface conversions and type assertions
타입의 변환에 대한 섹션이다. 문서에서 Printf에서 % v를 받을 때 어떻게 핸들링하는지에 대해 설명하고 있다.
type Stringer interface {
String() string
}
var value interface{} // Value provided by caller.
switch str := value.(type) {
case string:
return str
case Stringer:
return str.String()
}
value.(type)을 통해 가능한 타입을 케이스 별로 분기를 나눈다. 이는 다시 말해 혼합된 타입을 사용할 수 있는 걸 의미한다.
이렇게 해서 원하는 타입으로 뽑아낼 수 있다. 예를 들어
str := value.(string)
이렇게 스트링 타입으로 변환 후 변수 설정이 가능하다 이렇게 되면 str의 타입은 string 이 된다.
만약 이런 벨류에서 뽑아낼 타입이 없다면? 컴파일 에러가 아닌 런타임 에러가 발생하게 된다. 이에 따라 go에서는 아래와 같은 방법 이 관용적으로 사용된다고 한다.
func main(){
if str, ok := value.(string); ok {
return str
} else if str, ok := value.(Stringer); ok {
return str.String()
}
}
이 섹션에 대해서 잘 이해가 가질 않아서 검색을 해보다 보니 assertion과 conversion에 대한 개념을 먼저 잡아야 했다.
assertion => 벨류 의 인터페이스 안에서 하나의 타입을 끄집어내는 것이 assertion conversion => 하나의 타입을 다른 타입으로 변환하는 것을 conversion이라고 한다. 아래 예시를 보자.
type MyType interface {
What() string
}
func PrintHolyMoly(t MyType) {
fmt.Println("HOlYMOLY", t.What())
}
type A struct {
a int
}
func (a A) What() string {
return fmt.Sprintf("This is A %v", a.a)
}
type B struct {
a int
}
func (b B) What() string {
return fmt.Sprintf("This is B %v", b.a)
}
func main() {
var a MyType
a = A{1} // Type asseriton worked so a is MyType right now
if b, ok := a.(B); ok { // Type assertion do one more for type conversion to a => b
a = b
} else {
fmt.Printf("Conversion type failed from MyType(A) to B))\n")
}
PrintHolyMoly(a)
}
interface MyType을 구현하는 A, B 가 있다. A를 B 타입으로 바꾸는 과정을 작성한 코드이다.
이렇게 타입을 바꾸기 위해서는 우선 타입추론을 통해 인터페이스 타입으로 뽑아 온다음 인터페이스 타입에서 다시 뽑아서 B로 바꾸는 것이 가능한지 확인 후 타입을 변환하는 과정이다.
다형성 때문에 내가 많이 헷갈린 거 같은데 다형성은 저렇게 interface 타입으로 생성한 함수(PrintHolyMoly(a))에서
저렇게 사용이 가능한 거지
A, B 가 동일한 인터페이스를 구현한다고 하더라도 A,B 간의 타입전환은 가능하나 중간 점검이 필요하다.
Interfaces and methods
인터페이스 매머드의 예로 핸들러 인터페이스를 든다 핸들러 인터페이스를 구현하고 있다면 http 요청을 처리할 수 있는 함수가 된다.
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
ResponseWriter는 Wirte 메서드가 있는데 이 메서드 덕분에 io.Wirter 가 들어가는 모든 값에 responseWriter 벨류를 집어넣을 수 있다 왜? 인터페이스 구현을 하고 있으니깐
serveHttp에 관련해 HandlerFunc을 조금 길게 설명하고 있다 그중 아래와 같이 타입을 시그니쳐 함수로 받을 수 있다. 예를 보자.
// The HandlerFunc type is an adapter to allow the use of
// ordinary functions as HTTP handlers. If f is a function
// with the appropriate signature, HandlerFunc(f) is a
// Handler object that calls f.
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(w, req).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, req *Request) {
f(w, req)
}
The blank identifier
go에서는 선언한 값에 대해서는 무조건 적인 사용이 필수적이다 그렇지 않다면 컴파일 에러가 발생하는데 이를 해결하기 위해 _선언을 허용한다.
1. 사용되지 않는 임포트 => 이 임포트를 함으로써 init 함수가 실행되어야 프로그램 이 실행될 때
2. for, map을 loop 돌때 => 인덱스 값에 대해 이용하지 않을 때
1번 케이스를 임포트 사이드 이펙트라고 하는데 고의 기본 정책이니 다른 임포트 할 때 도 주의할 필요가 있다.
Interface checks
자바 같은 언어와 달리 고에서는 인터페이스의 함수만 구현하면 그 자체로 인터페이스 타입을 받을 수 있게 된다. 이에 따라 런타임 시점에 인터페이스에 서 타입을 끄집어내는 type assertion 이 가능하다. 예시로 제시하는 marshaler에 대해 알아보자.
우선 Go에서 엔코딩/디코딩, 마샬러 모두 비슷한 역할을 하는데 이에 대해 명확히 인지하고 사용해야 한다.
Encoding/Decoding 은 json의 문자를 스트링 또는 바이너리 데이터로 읽고 쓰기 하는 것을 의미한다.
Marshaling/UnMarshaling 은 JsonType으로부터 고 의 원시타입으로 맵핑하는 것 을 의미한다.
func main() {
var data Singer
var data2 Singer
jsonData := []byte(`
{
"Name" : "NewJeans",
"Title" : "Attention",
"DebutDate" : 2022
}
`)
verify := json.Valid(jsonData)
if verify {
json.Unmarshal(jsonData, &data)
fmt.Println(data)
}
json.NewDecoder(strings.NewReader(string(jsonData))).Decode(&data2)
fmt.Println(data2)
}
이에 동일한 결괏값을 받을 수 있다. 내부적으로 까보면 Decode 내에서 Unmarshal을 호출하고 있는 모습을 볼 수 있다. 즉 다시 말해
디코딩 은 버퍼에 들어있는 값을 들고 와 얼마샬 을 한다고 이해하면 될 거 같다.
349 업 버튼을 받은 답변 중에(https://stackoverflow.com/questions/21197239/decoding-json-using-json-unmarshal-vs-json-newdecoder-decode)
json.Decoder 는 나의 데이터가 io.Reader 에서 부터 온다면 혹은 스트림 데이터로부터 다양한 값을 디코딩해야 한다면 사용하고,
json.Unmarshal 은 이미 json 데이터가 메모리에 존재한다면 사용하라고 한다.
var _ json.Marshaler = (*RawMessage)(nil)
예시에서 이렇게 빈칸지시자를 활용해서 오로지 타입 체크만 할 때도 사용된다고 한다. 이는 type conversion 이기 때문에 컴파일 시점에 잡을 수 있다.
Embedding
고에서는 서브클래싱 의 타입 핸들? 드리븐? 개념을 제공하지 않는다? 무슨 의미인지 모르겠으나 고에서는 클래스 개념과 상속의 개념이 없어서 위와 같은 말을 한다고 생각된다. 이 문장 이후 제시된 대안으로
구조체 혹은 인터페이스의 임베딩 타입에 의해 구현된 일부분을 가져올 수 있다라고 강조한다. brrow라는 표현을 강조하는데 예시를 확인해 보자.
글을 읽어보면 자바의 class extend 가 생각난다.
subclass에서 superclass를 접근하는 개념과 유사하게 생각하면 될 거 같다 단지 구현의 차이만 있지 의미하는 바가 매우 유사하다.
글에서 제시된 io reader, writer 그리고 이걸 랩핑 하는 readwriter 가 있다면 reader와 writer에 readwriter 인스턴스가 접근할 수 있다.
예시를 보면 보다 이해가 확고해진다.
func main() {
type animal struct {
name string
age int
}
type cat struct {
animal animal
breed string
}
c := &cat{
animal{"somi", 12},
"Persian",
}
fmt.Printf("Breed is %v, name is %v , age is %v", c.breed, c.animal.name, c.animal.age)
// Breed is Persian, name is somi , age is 12
}
연속된. 을 이용해 랩핑 된 값들을 꺼내서 사용할 수 있다. 자바와 매우 유사한 부분인 것 같다.
이런 임베딩 타입의 문제점으로 제시되는 부분이 깊이에 따른 동일한 이름의 필드가 존재한다면?
이에 대한 문제는 매우 심플하게 해결된다. 각 깊이별로 이름이 따로 존재하기 때문에 깊이에 맞는. 을 이용해 체이닝 하면 된다.
두 번째로 동일한 깊이에 동일한 이름이 존재한다면? 이건 그냥 오류다 애초에 컴파일조차 허용 되지 않는다. 같은 구조체 안에 같은 이름 이라니 끔찍하다.
func main() {
arr := [3]int{1, 2, 3}
arr2 := [3]int{}
arr2 = arr
fmt.Printf("Type is %T, Point is %p, Values %v\n", arr, &arr, arr)
fmt.Printf("Type is %T, Point is %p, Values %v\n", arr2, &arr2, arr2)
}
결괏값
Type is [3] int, Point is 0x1400012e018, Values [1 2 3] Type is [3]int, Point is 0x1400012 e030, Values [1 2 3]
다른 배열에 할당하면 이와 같이 전체복사가 발생된다. 메모리 주소의 생성이 보는 바와 같이 4바이트 int 값 3개 총 12바이트 늘어난 e030부터 시작되는 것도 재밌는 포인트인 것 같다.
- 만약 함수변수로 사용한다면 이건 포인터 타입이 아닌, 카피 값이 넘어간다.
func main() {
arr := [3]int{1, 2, 3}
func(arr [3]int) {
fmt.Println("In Function")
fmt.Printf("Type is %T, Point is %p, Values %v\n", arr, &arr, arr)
}(arr)
fmt.Printf("Type is %T, Point is %p, Values %v\n", arr, &arr, arr)
}
결괏값
In Function Type is [3] int, Point is 0x140000ac030, Values [1 2 3] Type is [3]int, Point is 0x140000 ac018, Values [1 2 3]
보는 바와 같이 익명함수는 arr [3] int 를인자로 받는 함수이다. 거기에 기존에 선언한 arr를 넘겨주었지만 보는 바와 같이 다른 주소값을 반환하게 된다. 다시 말해 arr는 포인터 값이 아니기 때문에 레퍼런스 복사가 아닌 값복사가 발생되어 새로운 값을 할당하는 것이다.
- 배열의 크기는 하나의 타입이다.
배열의 크기 자체가 타입이라는 말은 단순하게 그냥 위에서 선언한 함수에서 인자로 [5] int를 받는다고 하면 바로 컴파일 에러가 발생한다.
위에서 말한 이유를 생각한다면 저렇게 받아야만 한다 왜? 값 복사가 일어날 때 메모리 낭비, 데이터 유실 이 되지 않으려면 정확하게 계산된 메모리 값 주소를 할당해주어야 하기 때문이다.
저 문서에서 값을 가지는 속성 또한 매우 유용할 수 있으나 비싸다고 한다. 그래서 만약 c와 같은 방식으로 구현하고 싶다면 go에서도 가능하다
func main() {
arr := [3]int{1, 2, 3}
func(arr *[3]int) {
fmt.Println("In Function")
fmt.Printf("Type is %T, Point is %p, Values %v\n", arr, &arr, arr)
}(&arr)
fmt.Printf("Type is %T, Point is %p, Values %v\n", arr, &arr, arr)
}
결괏값
Type is *[3] int, Point is 0x14000120018, Values &[1 2 3] Type is [3]int, Point is 0x1400012 e018, Values [1 2 3]
주소값을 넘기고 포인터 타입으로 받으면 손쉽게 해결 가능하다. 그러나 이러한 구현 방식은 고 에 어울리지 않는다고 한다. 이에 대한 해결책으로 슬라이스를 제시하는데 바로 가보자.
Slices
슬라이스는 가장 보편적이고 강력하며 편리한 데이터의 연속적인 인터페이스라고 설명한다. 통상 인터페이스{} 이렇게 하면 모든 타입을 소화할 수 있는 마법의 키워드이다. 문서에서도 대부분의 내장라이브러리 의 배열 관련 된 부분은 모두 슬라이스로 처리한다고 한다.
읽다 보면 엄청 강조하는 부분 중 하나가 바로 슬라이스는 레퍼런스를 홀드 한다고 한다. 즉 배열과 달리 레퍼런스를 홀드 하게 되면 함수 인자 혹은 선언 시에 값 복사가 아닌 레퍼런스 참조를 하게 된다는 의미이다.
그래서 위에 고 에 구현 방식에 어울리지 않는다고 하는데 한번 확인해 보자.
func main() {
fmt.Printf("Type is %T, Point is %p and arr[0] Point is %p value are %v \n", arr, &arr, &arr[0], arr)
fmt.Printf("Type is %T, Point is value for %p and arr[0] Point is %p, value are %v \n", arr2, &arr2, &arr2[0], arr2)
}
Type is []int, Point is 0x1400000c030 and arr[0] Point is 0x1400001c090 value are [1 2 3]
Type is []int, Point is value for 0x1400000c048 and arr[0] Point is 0x1400001c090, value are [1 2 3]
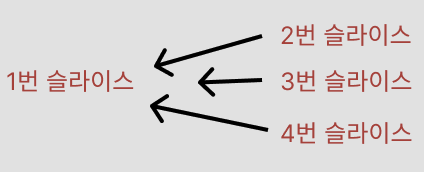
주의해서 볼 점은 여기서 arr2의 주소값은 물론 arr와 다르다 다만 arr2 [0]의 주소값을 보면 바로 arr [0]의 주소값을 가리킨다 다시 말해 아래 등호가 성립한다.
주소 arr2!= 주소 arr / 주소 arr [0] == arr2 [0]
이렇게 되면 당연히 복사가 일어나지 않기 때문에 위 배열과 같은 포인터 타입과 주소의 작업을 하지 않아도 된다.
위의 특징 외에도 슬라이스 하면 길이 없는 배열을 가장 먼저 떠올리게 된다. 이걸 가능하게 해주는 append 함수에 대해서 문서에서 준 예시를 보자.
func Append(slice, data []byte) []byte {
l := len(slice)
if l + len(data) > cap(slice) { // reallocate
// Allocate double what's needed, for future growth.
newSlice := make([]byte, (l+len(data))*2)
// The copy function is predeclared and works for any slice type.
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:l+len(data)]
copy(slice[l:], data)
return slice
}
기본적인 슬라이스를 선언해서 기존 사이즈 + 현재 들어오는 데이터 *2 만큼의 사이즈를 늘려주는데 자바의 어레이 리스트 내부 로직 중 grow()와 매우 유사하다. copy(목적지, 소스)인 형태이다 카피 구현 설명에 가보면 소스를 목적지로 오버래핑 한다고 되어있다.
추가적으로 인트 리턴 값이 있으나 이는 변경된 요소의 개수이다.
다시 말해 사이즈를 늘리는 하나의 새로운 슬라이스를 만들고 그에 현재 요소들을 복사해 넣어주고 리턴해주는 방식이다. 그래서 보통 append 빌트인 함수 사용여부를 볼 때 리턴 받은 슬라이스를 대입하곤 한다.