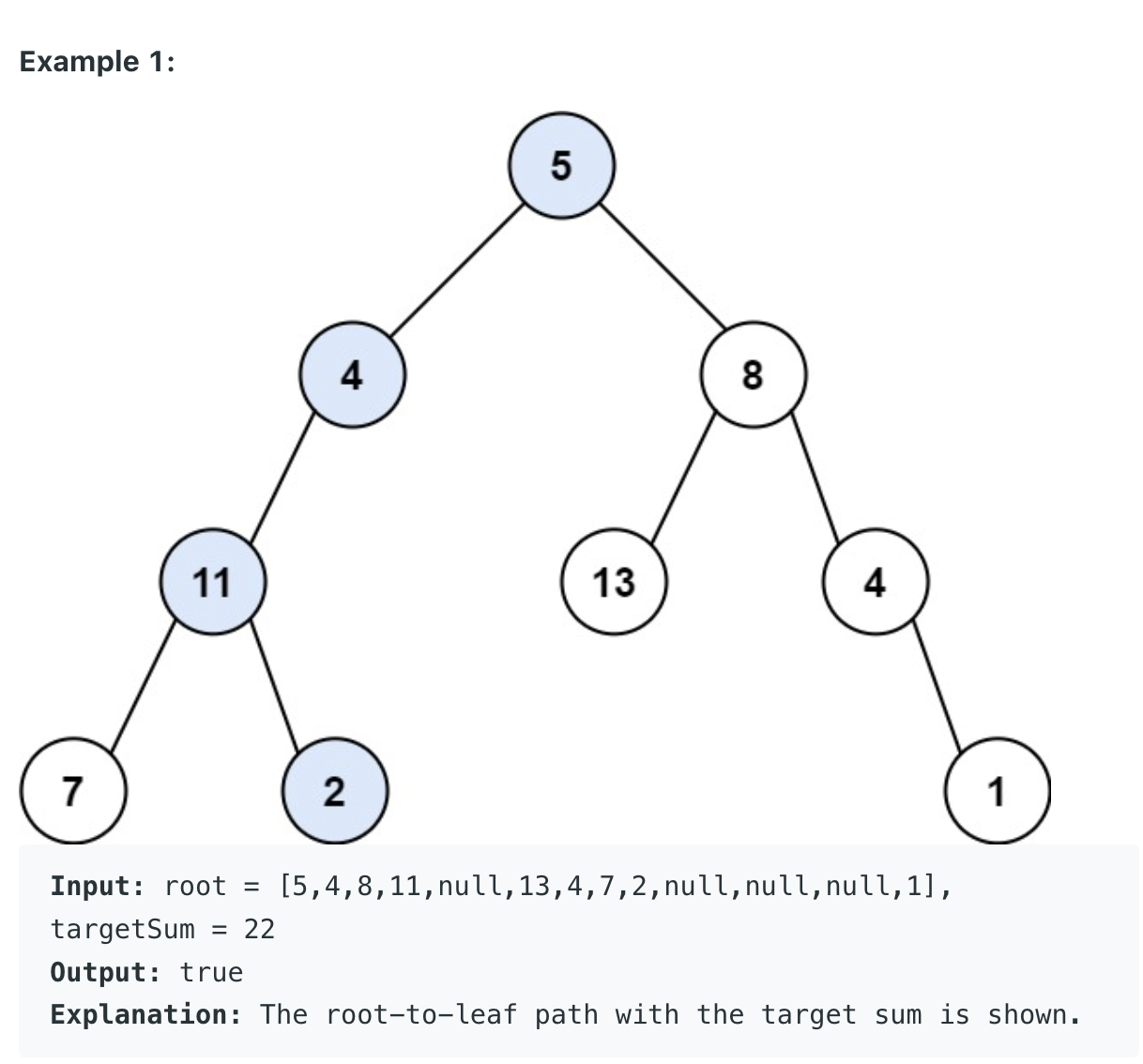
주어진 배열 과 값이 나오고 배열 내에서 해당 값을 지워서 리턴해주면 되는 간단한 문제이다.
다만 문제의 조건상 에 추가적인 메모리 가 없기 떄문에 배열 자체를 수정해서 리턴 해야한다.
class Solution {
public int removeElement(int[] nums, int val) {
int left =0;
for(int i=0;i<nums.length;i++){
if(nums[i] != val){
int tmp = nums[left];
nums[left++] = nums[i];
nums[i] = tmp;
}
}
return left;
}
}
left 값 하나 를 선정해서 투포인터 느낌으로 스왑 해가면서 풀었다. for loop 자동으로 증가하는 값을 right 로 생각하면 보다 쉽게 풀듯하다.
나름 난감했던 문제 였다. Stack 을 이용하지 않고 구현을 해보려고 노력하다 보니 그런거 같다.
class Solution {
public int[] plusOne(int[] digits) {
int len = digits.length-1;
StringBuilder answer = new StringBuilder();
int willAdd = 1;
for (int i = len; i >=0 ; i--) {
int next = digits[i] + willAdd;
answer.append(next%10);
if(next > 9) willAdd = 1;
else willAdd = 0;
}
if(willAdd == 1) answer.append(1);
int[] ans = new int[answer.length()];
for (int i = 0; i < ans.length; i++) {
ans[i] = answer.charAt(ans.length-1-i)-'0';
}
return ans;
}
}
1ms 가 나왔다 스택을 이용해서 속도적인 차이가 궁금해서 바로 구현해 봤다.
class Solution {
public int[] plusOne(int[] digits) {
Stack<Integer> stack = new Stack<>();
int len = digits.length-1;
int willAdd = 1;
for (int i = len; i >= 0; i--) {
int val = digits[i]+willAdd;
stack.push(val%10);
if(val > 9) willAdd = 1;
else willAdd = 0;
}
if(willAdd == 1) stack.push(1);
int[] answer = new int[stack.size()];
for (int i = 0; i < answer.length; i++) {
answer[i] = stack.pop();
}
return answer;
}
}
2ms 가 나온다 더 느리다 . 스택은 백터 를 상속받아서 구현 된 클래스다. 따라서 스레드 세이프 하다는 의미이다. 대부분의 함수에 syncronize 가 걸려있다.
동기화가 제거된 버전인 Deque 를 사용해보자 보통 queue , stack 에서 deque 를 사용하면 성능적인 측면에서 좋은 효과가 있다 왜 ?
스레드 세이프 하지 않으니깐. 1ms 가 나온다.
다른 사람의 풀이를 한번 확인해보자.
class Solution {
public int[] plusOne(int[] digits) {
int n = digits.length;
for(int i=n-1; i>=0; i--) {
if(digits[i] < 9) {
digits[i]++;
return digits;
}
digits[i] = 0;
}
int[] newNumber = new int [n+1];
newNumber[0] = 1;
return newNumber;
}
}
와.... 생각지도 못했던 부분이다. 물론 9 이하인경우 +1 해서 리턴 생각을 했지만 구현의 구체적인 방향성이 떠오르지 않아 위와같이 작성했는데.... 0ms 나온다. 저 9이하 리턴 부분이 최적화 가 완성된 부분이기떄문에 2배이상 빠른것 같다.
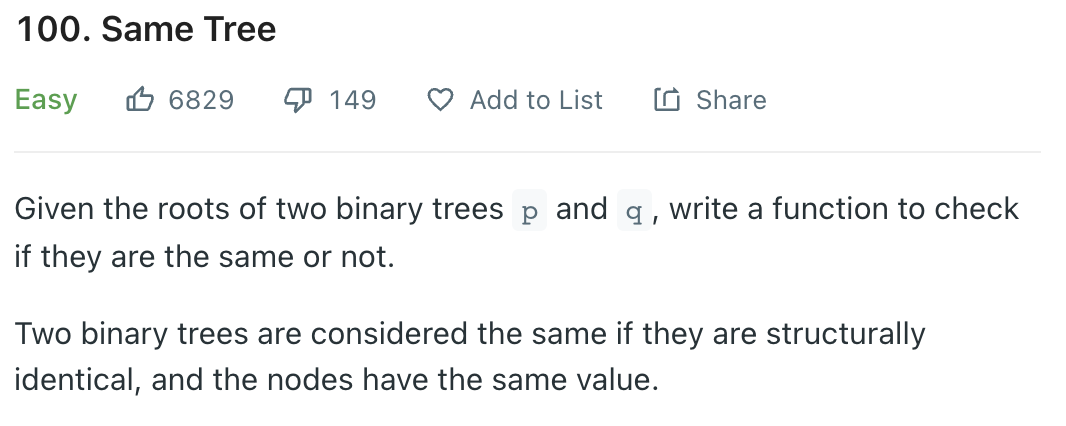
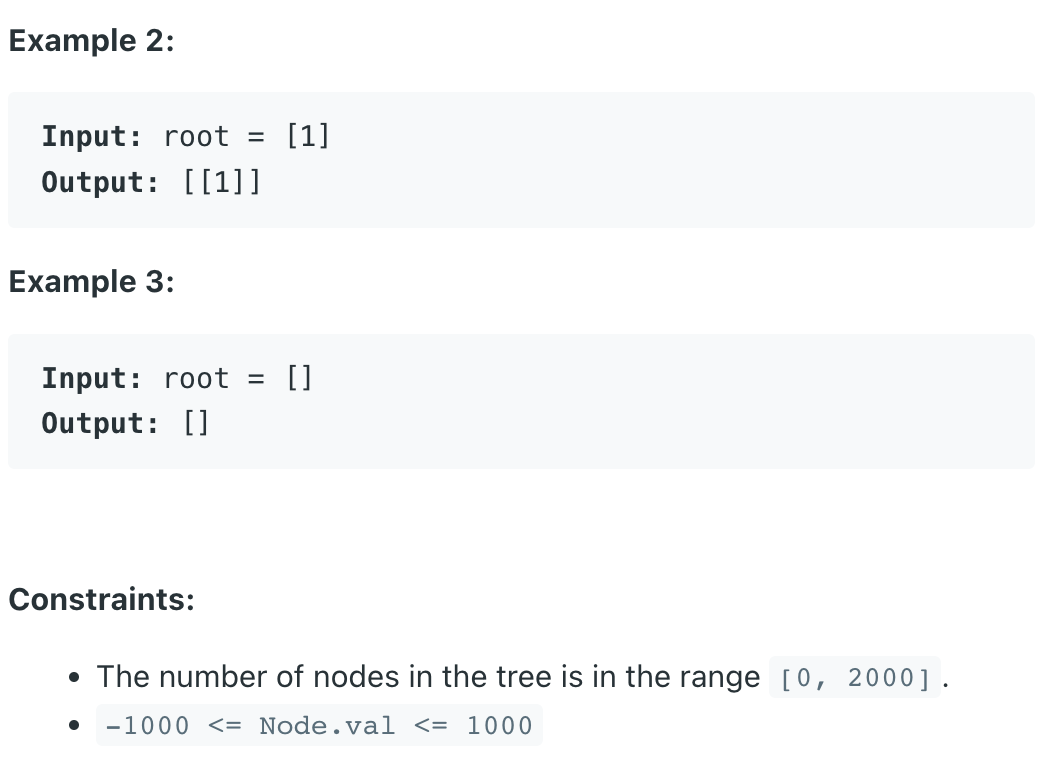
릿코드 답게 예상하지 못한 예외 케이스가 존재한다 ㅎㅎ, 풀이 의 과정은 2개의 2 덱을 선언해서 각각의 트리를 bfs로 순환해서 타 줄 것이다. 대신 그 중간에 null 값은 들어가지 못하게 예외처리를 분명하게 해주어야 한다. 이렇게 해도 통과되는 이유는 양쪽의 노드가 동일한 노드인지를 확인해주는 것이기 때문에 null 값은 체크 안 하고 넘겨주면 된다. if 처리가 복잡해서 그렇지 시간적 여유를 가지고 천천히 작성하면 한 번에 통과될 수준의 문제이다.
이 코드가 이해가 안 된다면 뒤에 문제들 은 전부 손볼 수가 없다. 확실히 이해하고 넘어가자.
참고로 모든 트리 순회 문제는 dfs 풀이가 2000배 섹시하다. 내가 좋아하는 풀이법이니 첨부하자. Dfs풀이
음? ㅋㅋㅋ 위의 문제가 정확히 일치하는 트리노드를 찾는 것이라면 이건 대칭되는 트리 노드를 찾는 것이다. 즉 위의 코드에서 q에 들어가 탐색할 대상이 deque 1 은 기존과 동일하게 그렇지만 deque 2는 기존과 반대로 넣어주면 해결되는 문제이다. 이해가 안 된다면 4층 레이어도 그려 본다면 느낌이 올 것이다. 풀이를 보자 위의 풀이와 다를게 크게 없다.
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null)
return res;
levelOrderHelper(res, root, 0);
return res;
}
public void levelOrderHelper(List<List<Integer>> res, TreeNode root, int level) {
if (root == null)
return;
List<Integer> curr;
if (level >= res.size()) {
curr = new ArrayList<>();
curr.add(root.val);
res.add(curr);
} else {
curr = res.get(level);
curr.add(root.val);
//res.add(curr); // No need to add the curr into the res, because the res.get(index) method does not remove the index element
}
levelOrderHelper(res, root.left, level + 1);
levelOrderHelper(res, root.right, level + 1);
}
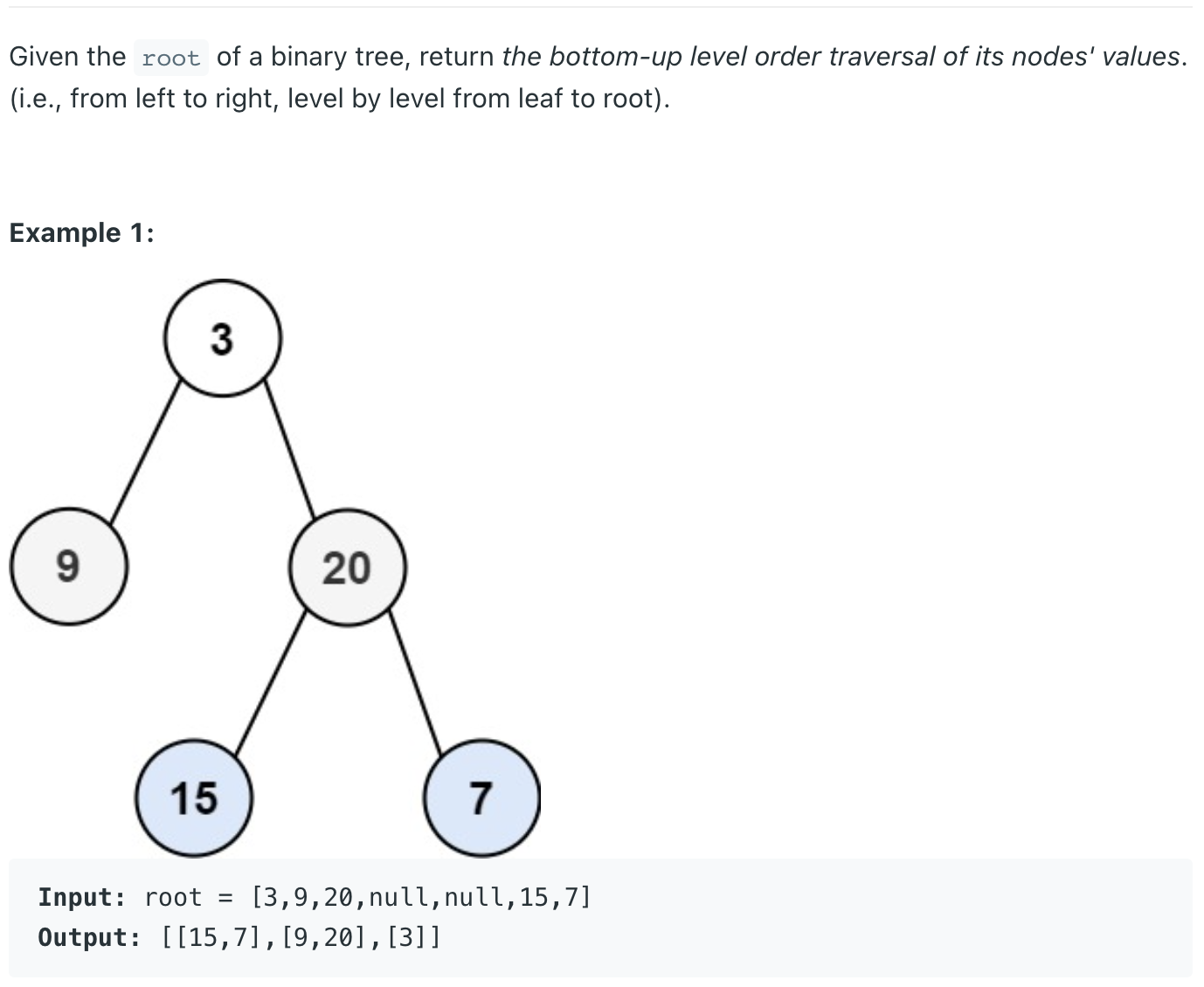
class Solution {
public List<List<Integer>> levelOrderBottom(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if(root == null) return result;
Deque<TreeNode> q = new ArrayDeque<>();
q.add(root);
while(!q.isEmpty()){
int n = q.size();
List<Integer> attach = new ArrayList<>();
for(int i=0;i<n;i++){
TreeNode cur = q.poll();
attach.add(cur.val);
if(cur.left != null) q.add(cur.left);
if(cur.right != null) q.add(cur.right);
}
result.add(attach);
}
Collections.reverse(result);
return result;
}
}
이렇게 말고도 정답을 linkedList로 생성해서 result.add(0, attach); 이런 식으로 하는 사람도 있었다. 확실히 리버스 보다 링크드 리스트 앞으로 삽입 하느것이 빠르다 속도적인 측면에서의 차이는 없었으나 제출자 들 사이에서 의 속도 차이는 많이 유의미했다.
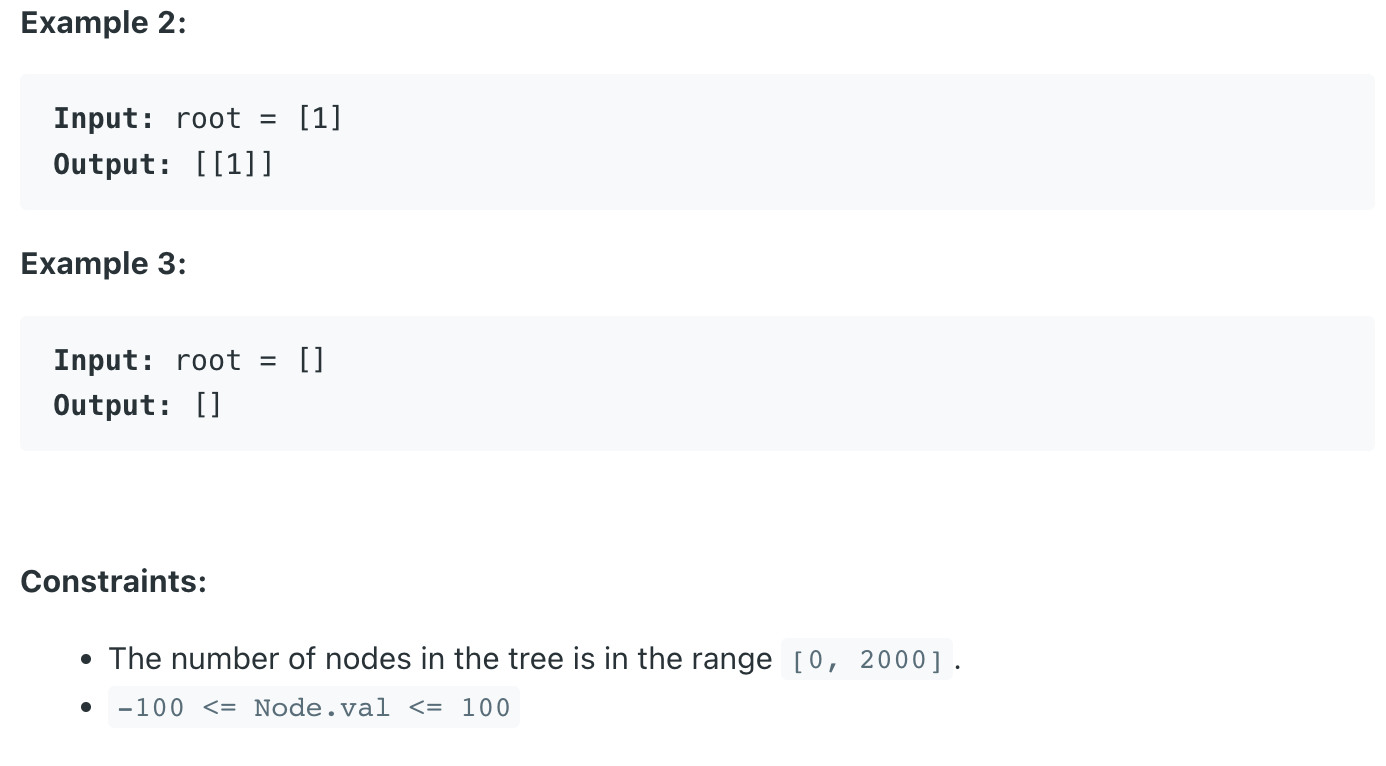
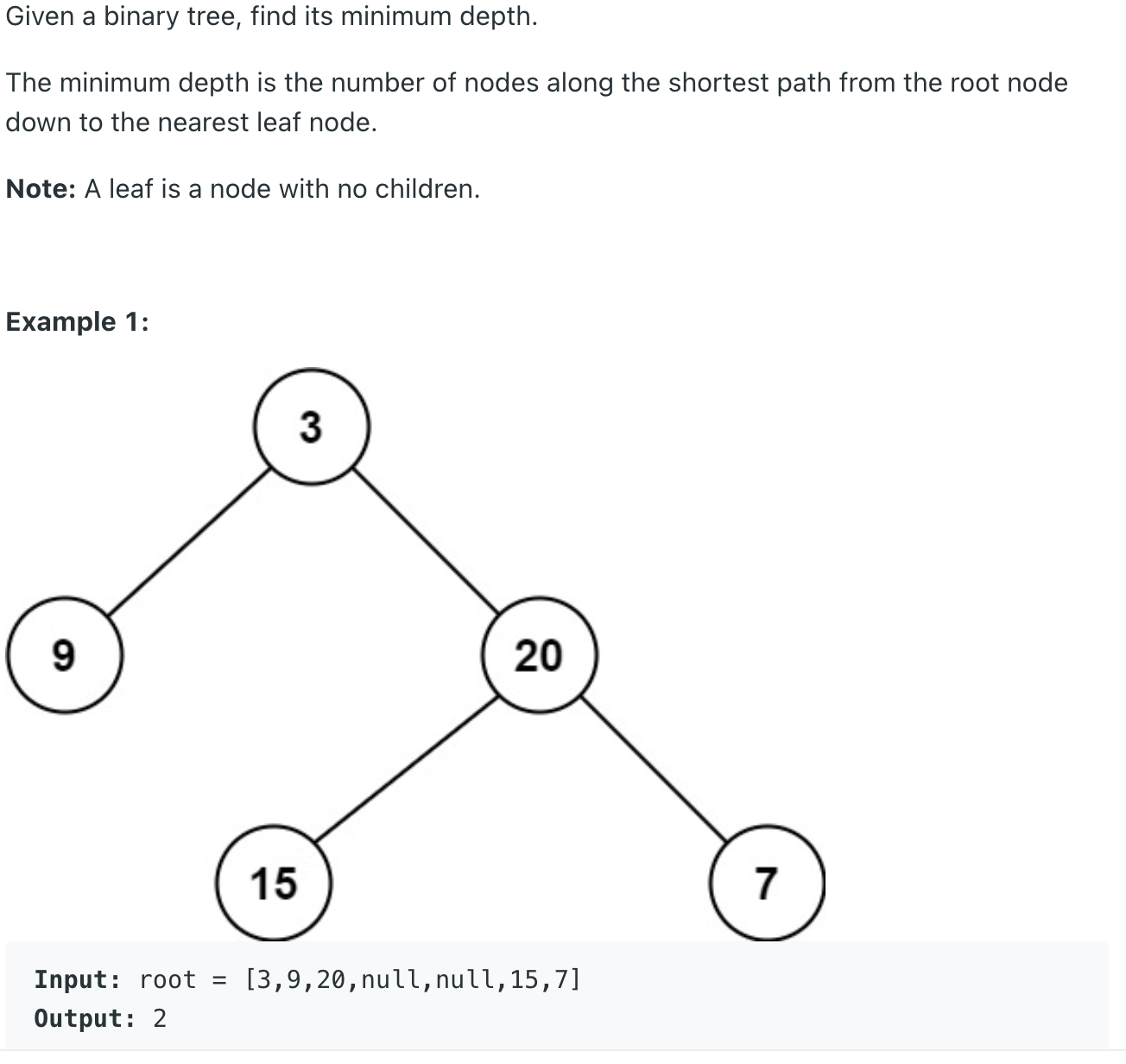
음? 이번에는 트리 깊이의 최솟값을 구하면 된다 bfs 돌다가 처음 자식들이 null 인 경우의 깊이를 반환해주면 된다.
class Solution {
public int minDepth(TreeNode root) {
if(root == null) return 0;
int d = 1;
Deque<TreeNode> q = new ArrayDeque<>();
q.offer(root);
while(!q.isEmpty()){
int n = q.size();
// for each level
for(int i=0;i<n;i++){
TreeNode node = q.poll();
if(node.left == null && node.right == null){
return d;
}
if(node.left != null){
q.offer(node.left);
}
if(node.right != null){
q.offer(node.right);
}
}
d++;
}
return d;
}
}
특별할 것 없는 코드이다. 위에 설명한 대로 최초 만난 자식 없는 노드는 리프임으로 현재 깊이를 반환해준다.
이 문제는 dfs 보다는 bfs 가 더 괜찮다고 생각한다. 왼쪽에는 노드 한 개가 있지만 오른쪽은 노드가 500 층까지 있다고 생각하면 bfs의 경우 왼쪽 노드 한 개를 탐 새하고 리턴 하지만, dfs의 경우 반대쪾 500 개 모두를 탐색해야 한다. 그래도 dfs 코드는 섹시하니깐 첨부한다.
public class Solution {
public int minDepth(TreeNode root) {
if(root == null) return 0;
int left = minDepth(root.left);
int right = minDepth(root.right);
return (left == 0 || right == 0) ? left + right + 1: Math.min(left,right) + 1;
}
}
이 문제는 트리 가 주어지고 타깃 값이 주어지면 현재 시작점부터 리프까지 그중에 타겟값이 존재하냐는 문제이다. 처음 - 값의 제한상을 보지 못해서 트리의 bfs를 진행함과 동시에 가중치를 넘겨주었다 이 가중치가 타깃보다 크다면 q에 추가를 하지를 않았는데 제한사항을 보니 - 값이 있기에 위의 최적화 부분을 제외해 주었다.
아 o(logn) 꼴도 보기싫다 ㅋㅋㅋㅋ.. 지문이 제법 길지만, 뭐 대충 이거는 pivot 에 의해 정렬 이 된 상태의 배열이 주어진다. 위에 예시가 착하게 나와 있으니 예시를 보면 이해하기 쉽다. 음 ? 이해가 왜 미디엄 레벨 이지 ?
좌우 포인터 잡고 하나씩 줄여가기로 결정
class Solution {
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
int idx = -1; // set default as -1
while (left <= right) {
if (nums[left] == target) {
idx = left;
break;
} else {
left++;
}
if (nums[right] == target) {
idx = right;
break;
} else {
right--;
}
}
return idx;
}
}
특별할것 하나 없는 코드이다. 말 그대로 -1 을 디폴트로 설정해서 좌우 번갈아 가면서 찾아준다. 주어진 문제에서 숫자는 고유하기 떄문에 이러한 방법이 가능하다.
다른사람들의 코드를 보자.
public class Solution {
public int search(int[] A, int target) {
int lo = 0;
int hi = A.length - 1;
while (lo < hi) {
int mid = (lo + hi) / 2; // 미드 값 구하기
if (A[mid] == target) return mid;
if (A[lo] <= A[mid]) {
//현재 미드값 과 레프트 값의 비교 만약 이게 성립이 된다면 현재 범위는 로테이트 된 값 이 있는 부분이다.
if (target >= A[lo] && target < A[mid]) {
hi = mid - 1; //로테이된 왼쪽 부분에 위치하는 조건이다.
} else {
lo = mid + 1; // 로테이트된 오른쪽 부분에 위치하는 조건이다.
}
} else {
if (target > A[mid] && target <= A[hi]) {
lo = mid + 1;
} else {
hi = mid - 1;
}
}
}
return A[lo] == target ? lo : -1;
}
이 사람은 이분탐색 그대로 구현했다. 대신 미드 값에 따른 이동 포인터를 좌우 비교를 통해 현재 진행되는 방향이 로테이트 된 방향인지 아닌지를 모두 체크하는 if 문을 넣어 주었는데 비교적 코드가 직관적 이여서 가져왔다.
음 만약 1,2,3,4,5,6,7 이란 코드가 있고 4,5,6,7,0,1,2,3 이렇게 피벗 4 에 변경이 된다면 4 5 6 7 / 0 1 2 3 이렇게 나누어서 생각해 볼수 있다 여기서 찝은 미드의 값과 왼쪽 과 오른쪽 비교를 해주었을때 어느 부분을 찝었는 지 알수 있다. 또한 타겟을 이용해 범위를 명확히 줄여 나가는 것이 참 신기한 아이디어 같다.
주어진 num 범위 안에서 타겟 에 해당하는 범위를 출력하는것이다. 이미 정렬 되어진 상태이니 이분탐색으로 빠르게 해당 값을 찾고
그 값으로 부터 좌우로 증가하면서 알맞은 값을 찾는것이다.
코드를 보자.
class Solution {
public int[] searchRange(int[] arr, int target) {
int left = -1;
int right = -1;
int nLeft = 0;
int nRight = arr.length - 1;
int idx = -1;
while (nLeft <= nRight) {
int mid = nLeft + (nRight - nLeft) / 2;
if (arr[mid] < target) {
nLeft = mid + 1;
} else if (arr[mid] == target) {
idx = mid;
break;
} else {
nRight=mid-1;
}
}
if (idx == -1)
return new int[] { left, right };
left = idx;
right = idx;
while (arr[left] == target) {
if (left-1>=0 &&arr[left - 1] == target) {
left--;
} else {
break;
}
}
while (arr[right] == target) {
if(right+1 >= arr.length){
break;
}
if (right+1<arr.length && arr[right + 1] == target) {
right++;
} else {
break;
}
}
System.out.println(left + " " + right);
return new int[] { left, right };
}
}
left , right 는 -1 로 지정을 해주고 문제에서 못찾으면 -1 리턴 하라고 했으니 이니셜 지정 해주자. 가운데 값을 찾은 후 말그대로 while 돌려가며 왼쪽 끝 오른쪽 끝을 이동하며 찾는데 12 ms ~ 15ms 정도 나온다. 매우 느린 코드다 마음에 들지 않는다. 양쪽으로 이분탐색을 다시해봐도 별반 차이가 없다... ㅎㅎ
고수들의 코드를 봐보자.
public class Solution {
public int[] searchRange(int[] nums, int target) {
int[] result = new int[2];
result[0] = findFirst(nums, target);
result[1] = findLast(nums, target);
return result;
}
private int findFirst(int[] nums, int target){
int idx = -1;
int start = 0;
int end = nums.length - 1;
while(start <= end){
int mid = (start + end) / 2;
if(nums[mid] >= target){
end = mid - 1;
}else{
start = mid + 1;
}
if(nums[mid] == target) idx = mid;
}
return idx;
}
private int findLast(int[] nums, int target){
int idx = -1;
int start = 0;
int end = nums.length - 1;
while(start <= end){
int mid = (start + end) / 2;
if(nums[mid] <= target){
start = mid + 1;
}else{
end = mid - 1;
}
if(nums[mid] == target) idx = mid;
}
return idx;
}
이분탐색 을 이렇게 반반 나눠서 한다. 와 미쳤다.. 생각 하지도 못했다.... 정형화된 이분탐색 에서 break else 에 변화를 주고 점점 가지치기 해나가는데 와... 멋진 코드이다.
public class Solution {
public int[] searchRange(int[] A, int target) {
int start = Solution.firstGreaterEqual(A, target);
if (start == A.length || A[start] != target) {
return new int[]{-1, -1};
}
return new int[]{start, Solution.firstGreaterEqual(A, target + 1) - 1};
}
//find the first number that is greater than or equal to target.
//could return A.length if target is greater than A[A.length-1].
//actually this is the same as lower_bound in C++ STL.
private static int firstGreaterEqual(int[] A, int target) {
int low = 0, high = A.length;
while (low < high) {
int mid = low + ((high - low) >> 1);
//low <= mid < high
if (A[mid] < target) {
low = mid + 1;
} else {
//should not be mid-1 when A[mid]==target.
//could be mid even if A[mid]>target because mid<high.
high = mid;
}
}
return low;
}
}
와 이건 ㅋㅋㅋㅋㅋㅋ 아이디어의 발상이 참 대단하다. 찾고자 하는수에 +1 을 해서 그수를 찾고 그인덱스 -1 과 찾고자 하는 수 와 정말 멋진코드가 많다. 이걸보고 다시 내 코드보니 왜이리 구려보이 는지..... 내일 다시풀때는 이 코드로 작성해보자.
주어진 숫자 배열 안에 연속된 부분 배열 중 가장 큰 값을 리턴하면 되는 심플 한 문제이다. 문제만 심플하지 생각할 것이 꽤 많은 문제였다.
문제풀이를 하면서 다양하게 접근했다. 저기 주어진 예시들 은 길고 특별한 케이스이니 심플하게 만들어서 생각해보자.
[-3,2,3,-1]
뭐 있나 1번 부터 다 쓰자...
1번 인덱스 : 뭐 할 게 없다 그냥 리턴해줘야 한다...-3
2번 인덱스 : [-3], [2] / [-3,2] 오 뭔가 느낌이 온다.
3번 인덱스 : [-3], [2], [3] / [-3,2], [2,3] / [-3,2,3] 왔다, 약간 dp 스럽게 풀어야 하는 건가 싶었다.
현재 인덱스까지 진행된 것 중 버릴 거 버리면서 진행한다면 나쁘지 않은 효율이 나올 것 같았다.
뭘 어떻게 버려 주어야 할까 고민하다가, 현재 진행 중인 값에 다음 값을 더해서 그 값이 다음값 보다 작다면? 뒤에 까지 다 더한 것은 쓸모가 없어진다.. -2 1 -3을 예로 들어보자 -2 1 => -1 인 상태에서 -3 을 더하면? -4인데 우리는 연속된 수를 구해야 하니 버리자 대신 저 앞에 까지 더해진 부분을 따로 기록을 해 두어야 할 것이다.
class Solution {
public int maxSubArray(int[] arr) {
if(arr.length == 1) return arr[0];
int p1 = 0;
int p2 = 1;
int maxSum = arr[p1];
int currentSum = arr[p1];
while(p2<arr.length){
int nextCur = currentSum + arr[p2];
if(nextCur < arr[p2]){
p1 = p2;
currentSum = arr[p2];
}else{
currentSum = nextCur;
}
maxSum = Math.max(maxSum,currentSum);
p2++;
}
return maxSum;
}
}
오늘 two pointer 강의를 듣고 와서 그런가 엄청 비슷하게 푼 거 같은데 허점이 존재한다.... p1을 선언해 놓고 쓰지도 않는다...... 고수들의 코드를 보자.
class Solution {
public int maxSubArray(int[] nums) {
int currSum = nums[0], result = nums[0];
for (int i=1;i<nums.length;i++){
currSum = Math.max(nums[i], currSum + nums[i]);
result = Math.max(result, currSum);
}
return result;
}
}
호 올리 몰리...... math.max를 이렇게 선언하면서 깔끔하게 for 반복문으로 해결해 버리는 아름다운 코드이다. 조금 더 디스커스를 둘러보면 Kadane's Algorithm 이란 글로 엄청 아름답게 써놓은 글이 있다. 따로 퍼오기 좀 그러니 링크를 첨부하겠다.
개괄적으로 설명을 하자면 위의 풀이법 그대로가 카 데인 알고리즘이다. 글 설명 10줄보다 그림 이 훨씬 보기 편하니 아래 링크로 이동해서 확인하면 더 도움 이 됩니다. 보러 가기
이 사람이 작성한 글에 의하면 어느 부분이던 합이 - 에 도달한다면, 이걸 계속 가지고 있을 의미가 없기 때문에 합을 0으로 초기화시켜준다고 한다.
-2 1 -3 4 -1 2 1 -5 4 (예시 1번)
i = 0 일 때 합은 -2 가 되고 , 최대 합은 -2 , 합이 0 보다 작기 때문에 현재 합은 0으로 초기화된다.
i = 1 일 때 합은 0+1(현재 합을 0 으로 초기화 시켜서 전 인덱스에서) 이되고, 합이 1 이된다 최대합은 1
i = 2 일 때 합은 1 -3 -2 가 되고 최대합은 1, 현재합은 0으로 초기화된다 왜 ? 0보다 작아서
i = 3 일때 합은 0+4 4 가되고 최대합은 4, 현재합은 4 가된다
이런 식으로 쭉쭉 이어나가면 된다. 위 링크에 더 자세히 설명되어 있으니 참고 바랍니다.!!
자세히 다시 보니 브루트 포스 에서 내가 느낀 그 디피 느낌이 이 카데인 알고리즘 이였다 그냥 디피라고 하면 될걸 왜 굳이 이름을 이렇게 붙이는지 다시보니 도둑이 집터는 문제랑 매우 유사하다고 생각된다...... 현재 합과, 현재 인덱스 중 큰 것, 또 맥스 값과 큰 것을 비교하는 법 왜 항상 모든 블로그 혹은 유튜브 비디오에서 항상 브루트 포스를 먼저 하라고 하는지 다시 한번 느끼는 문제였다..