class Solution {
public int minDeletionSize(String[] strs) {
int answer = 0;
int len = strs[0].length();
for(int i=0;i<len;i++){
for(int j=1;j<strs.length;j++){
char a = strs[j].charAt(i);
char b = strs[j-1].charAt(i);
if( a < b){
answer++;
break;
}
}
}
return answer;
}
}
배열의 최대 크기 1000, 문자의 최대길이 100 => 2중 포문 돌려도 문제없다고 생각해서 바로 작성했다.
최초 작성시 에 i, j 를 이상하게 지정을 해버리는 바람에 indexOutOfRange 에러가 났다. 언제쯤 이런 잔 실수를 없앨수 있는지...
public boolean detectCapitalUse(String word) {
if (word.length() < 2) return true;
if (word.toUpperCase().equals(word)) return true;
if (word.substring(1).toLowerCase().equals(word.substring(1))) return true;
return false;
}
반대로 true 가 되는 조건만 을 subString 과 toUpperCase 를 이용해 깔끔하게 코드 를 구사했다.
그러나 toUpperCase 의 작동하는 방식을 보면 내부적으로 forLoop 를 돌려서 내부로직 수행후 String 을 리턴해준다.
하물며 subString 은 어떤가 String 은 불변 이다 따라서 클래스 내부 의 value 바이트 코드 배열을 arrayCopy 를 수행해 새로운 스트링을 만들어 뱉어준다. 즉 for 를 한번더 돈다는 의미이다. eqaul 또한 하나씩 비교하기 위해 forLoop 을 돈다
이렇게 수행 로직 만 보고 생각한다면 느릴수 밖에없다. 다만 이해하기 쉽다.
실제 업무에 투입되어 작성한코드 라면 사실 나는 이 코드 처럼 작성하고 싶다. 성능상의 문제가 있는 것 이 아니라면 코드 자체를 이렇게 두고 유지할것이다. 왜 ? 읽기 쉬운 코드가 최고니깐.
트리 내에 존재하는 엣지 를 타고 가장 합이 높은 부분을 구하는 문제이다. 어제와 유사한 문제라고 생각해서 비슷하게 접근했으나 머리가 대차게 깨져버렸다.
어제 와 유사한 코드로 접근하였으나 - 값의 여부와 한가지 패스 안에서는 길을 타고 다시 거슬러 올라오면 안 된다는 부분에서 신경이 쓰여 preorder를 사용했다. 중복을 처리해줄 방법이 없어 생각보다 애를 많이 먹었다...
if를 이용해서 틀릴 때마다 처리를 해주었으나. 99개 테스트 케이스에서 56 이 한계였다. preOrder, postOrder 전부 실패했다. prefix를 이용하기 위해 리스트 넘기는 방법, max를 이용해 현재 비교대상을 3번 비교하는 방법 전부 실패했다.
뭔가 잡힐듯 말듯한데 자꾸 실패해서 분하다...
약 1시간 정도 풀다가 실패해서 discuss를 보고 오니 내가 구해야 할 명확한 목적을 알고 나니 풀이가 쉬워졌다.
머리 깨진 풀이
class Solution {
int max;
public int maxPathSum(TreeNode root) {
List<Integer> list = new ArrayList<>();
max = Integer.MIN_VALUE;
helper(root, list);
int total = list.get(list.size()-1);
for (int i = 0; i < list.size()-1; i++) {
max = Math.max(Math.max(total,total-list.get(i)),max);
}
return max;
}
public void helper(TreeNode node, List<Integer> list){
if(node == null) return;
helper(node.left, list);
int previous = list.size() == 0 ? 0 : list.get(list.size()-1);;
list.add(previous+node.val);
max = Math.max(max,node.val);
helper(node.right,list);
}
}
트리 순회를 위해 helper를 선언해 중위 순회를 선택했다. 이유는 후위 순회를 하게 된다면 리프부터 타고 올라가야 하는데 이 기준점을 정해주기 가 생각보다 어려웠다. prefix를 사용해야 한다는 압박감 때문 인지. 후위 순회를 하게 되니 오류가 많이 생겼다.
디스커스에서 읽고 바로 풀이 방법을 바꾼 힌트 를 보자.
우리가 구해야 할 4가지 경우의 수가 있다.
1. 왼쪽 패스 + 현재 값
2. 오른쪽 패스 + 현재 값
3. 왼쪽 패스 + 오른쪽 패스 + 현재 값
4. 현재 값 자체로 위 값보다 큰 경우
이 4 가지를 명확히 하고 갔어야 했는데 이게 안되니 null 이 여러 번 들어간 깊이 있는 트리인 경우 오답이 나게 되는 것이다. ㅠ
위 4가지 힌트를 얻어서 작성한 풀이법이다.
class Solution{
int max = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
helper(root);
return max;
}
public int helper(TreeNode node){
if(node == null) return Integer.MIN_VALUE;
int left = helper(node.left);
int right = helper(node.right);
max = Math.max(max,Math.max(left,right));
max = Math.max(max,node.val);
max = Math.max(max,node.val+Math.max(left,0)+Math.max(right,0));
return node.val + Math.max(0,Math.max(left,right));
}
}
max 값을 비교할 Integer를 선언해주고 , 현재 값이 - 값이라면 무조건 0으로 초기화시켜주었다.
left 패스, right 패스를 각각 구하고 현 max와 패스의 합 +현재 값
그리고 현재 값에 패스 값 중 높은 값을 다음으로 넘겨주는 재귀를 작성하였다.
class Solution{
int value = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
int temp = process(root);
return Math.max(temp, value);
}
public int process(TreeNode head){
if(head == null){
return 0;
}
int leftTree = Math.max(0, process(head.left));
int rightTree = Math.max(0, process(head.right));
value = Math.max(value, leftTree + rightTree + head.val);
return Math.max(leftTree, rightTree) + head.val;
}
}
이 사람도 보면 참 깔끔하게 작성한 거 같다. 왼쪽 패스, 오른쪽 패스를 나누고 현재 값의 맥스를 왼쪽 오른쪽의 합과 현재 값을 이용하고 다음 재귀로 왼쪽 오른쪽 중 큰 값을 현재 값에 더해 넘겨준다.
maxValue = Math.max(maxValue, left + right + node.val);
작성할 때 난감 했던 부분이다. maxVaule를 현재 와 왼쪽 오른쪽 그리고 노드의 값을 합친 값으로 업데이트를 하는 것이 아닌가.
주어진 배열 과 값이 나오고 배열 내에서 해당 값을 지워서 리턴해주면 되는 간단한 문제이다.
다만 문제의 조건상 에 추가적인 메모리 가 없기 떄문에 배열 자체를 수정해서 리턴 해야한다.
class Solution {
public int removeElement(int[] nums, int val) {
int left =0;
for(int i=0;i<nums.length;i++){
if(nums[i] != val){
int tmp = nums[left];
nums[left++] = nums[i];
nums[i] = tmp;
}
}
return left;
}
}
left 값 하나 를 선정해서 투포인터 느낌으로 스왑 해가면서 풀었다. for loop 자동으로 증가하는 값을 right 로 생각하면 보다 쉽게 풀듯하다.
나름 난감했던 문제 였다. Stack 을 이용하지 않고 구현을 해보려고 노력하다 보니 그런거 같다.
class Solution {
public int[] plusOne(int[] digits) {
int len = digits.length-1;
StringBuilder answer = new StringBuilder();
int willAdd = 1;
for (int i = len; i >=0 ; i--) {
int next = digits[i] + willAdd;
answer.append(next%10);
if(next > 9) willAdd = 1;
else willAdd = 0;
}
if(willAdd == 1) answer.append(1);
int[] ans = new int[answer.length()];
for (int i = 0; i < ans.length; i++) {
ans[i] = answer.charAt(ans.length-1-i)-'0';
}
return ans;
}
}
1ms 가 나왔다 스택을 이용해서 속도적인 차이가 궁금해서 바로 구현해 봤다.
class Solution {
public int[] plusOne(int[] digits) {
Stack<Integer> stack = new Stack<>();
int len = digits.length-1;
int willAdd = 1;
for (int i = len; i >= 0; i--) {
int val = digits[i]+willAdd;
stack.push(val%10);
if(val > 9) willAdd = 1;
else willAdd = 0;
}
if(willAdd == 1) stack.push(1);
int[] answer = new int[stack.size()];
for (int i = 0; i < answer.length; i++) {
answer[i] = stack.pop();
}
return answer;
}
}
2ms 가 나온다 더 느리다 . 스택은 백터 를 상속받아서 구현 된 클래스다. 따라서 스레드 세이프 하다는 의미이다. 대부분의 함수에 syncronize 가 걸려있다.
동기화가 제거된 버전인 Deque 를 사용해보자 보통 queue , stack 에서 deque 를 사용하면 성능적인 측면에서 좋은 효과가 있다 왜 ?
스레드 세이프 하지 않으니깐. 1ms 가 나온다.
다른 사람의 풀이를 한번 확인해보자.
class Solution {
public int[] plusOne(int[] digits) {
int n = digits.length;
for(int i=n-1; i>=0; i--) {
if(digits[i] < 9) {
digits[i]++;
return digits;
}
digits[i] = 0;
}
int[] newNumber = new int [n+1];
newNumber[0] = 1;
return newNumber;
}
}
와.... 생각지도 못했던 부분이다. 물론 9 이하인경우 +1 해서 리턴 생각을 했지만 구현의 구체적인 방향성이 떠오르지 않아 위와같이 작성했는데.... 0ms 나온다. 저 9이하 리턴 부분이 최적화 가 완성된 부분이기떄문에 2배이상 빠른것 같다.
릿코드 답게 예상하지 못한 예외 케이스가 존재한다 ㅎㅎ, 풀이 의 과정은 2개의 2 덱을 선언해서 각각의 트리를 bfs로 순환해서 타 줄 것이다. 대신 그 중간에 null 값은 들어가지 못하게 예외처리를 분명하게 해주어야 한다. 이렇게 해도 통과되는 이유는 양쪽의 노드가 동일한 노드인지를 확인해주는 것이기 때문에 null 값은 체크 안 하고 넘겨주면 된다. if 처리가 복잡해서 그렇지 시간적 여유를 가지고 천천히 작성하면 한 번에 통과될 수준의 문제이다.
이 코드가 이해가 안 된다면 뒤에 문제들 은 전부 손볼 수가 없다. 확실히 이해하고 넘어가자.
참고로 모든 트리 순회 문제는 dfs 풀이가 2000배 섹시하다. 내가 좋아하는 풀이법이니 첨부하자. Dfs풀이
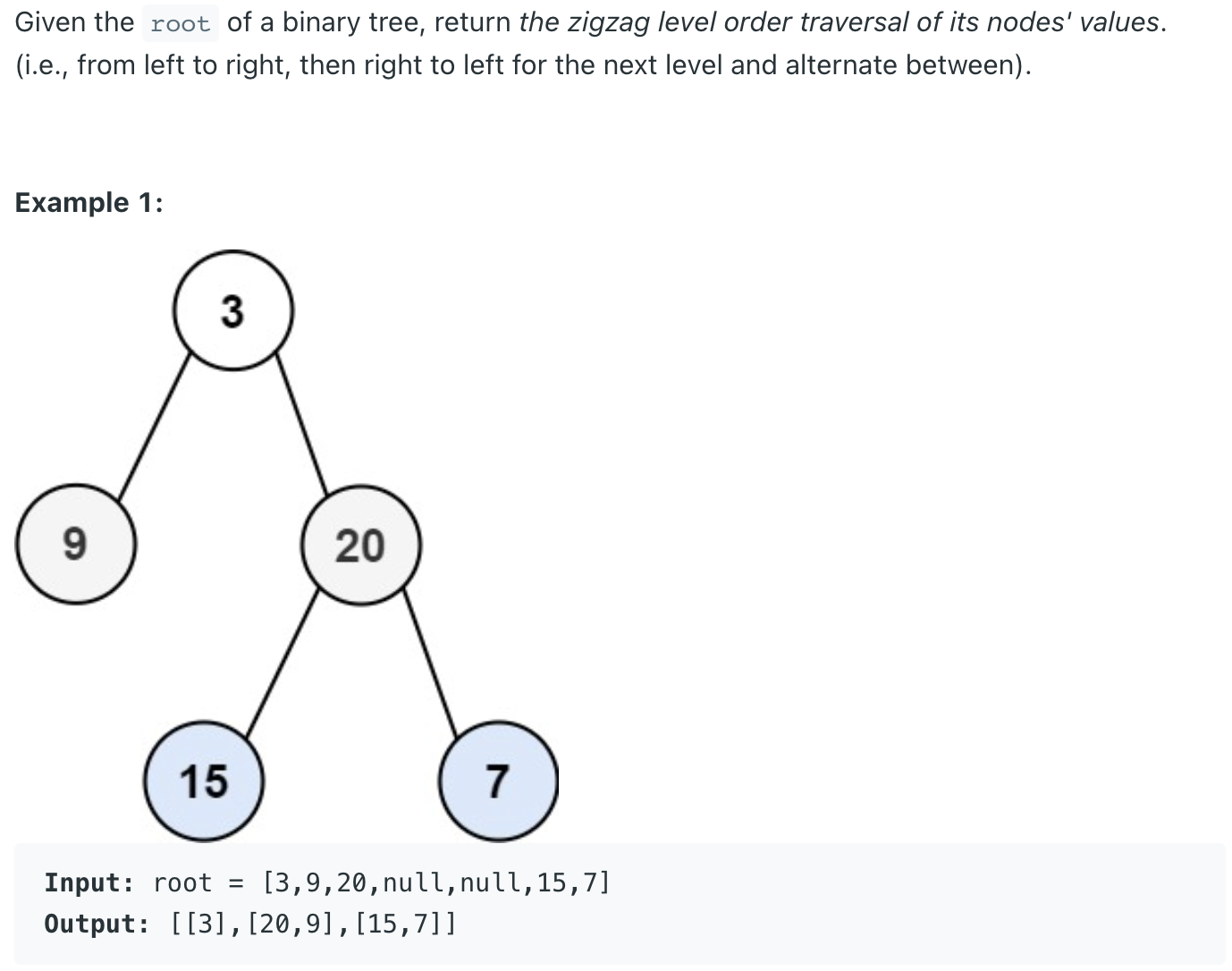
음? ㅋㅋㅋ 위의 문제가 정확히 일치하는 트리노드를 찾는 것이라면 이건 대칭되는 트리 노드를 찾는 것이다. 즉 위의 코드에서 q에 들어가 탐색할 대상이 deque 1 은 기존과 동일하게 그렇지만 deque 2는 기존과 반대로 넣어주면 해결되는 문제이다. 이해가 안 된다면 4층 레이어도 그려 본다면 느낌이 올 것이다. 풀이를 보자 위의 풀이와 다를게 크게 없다.
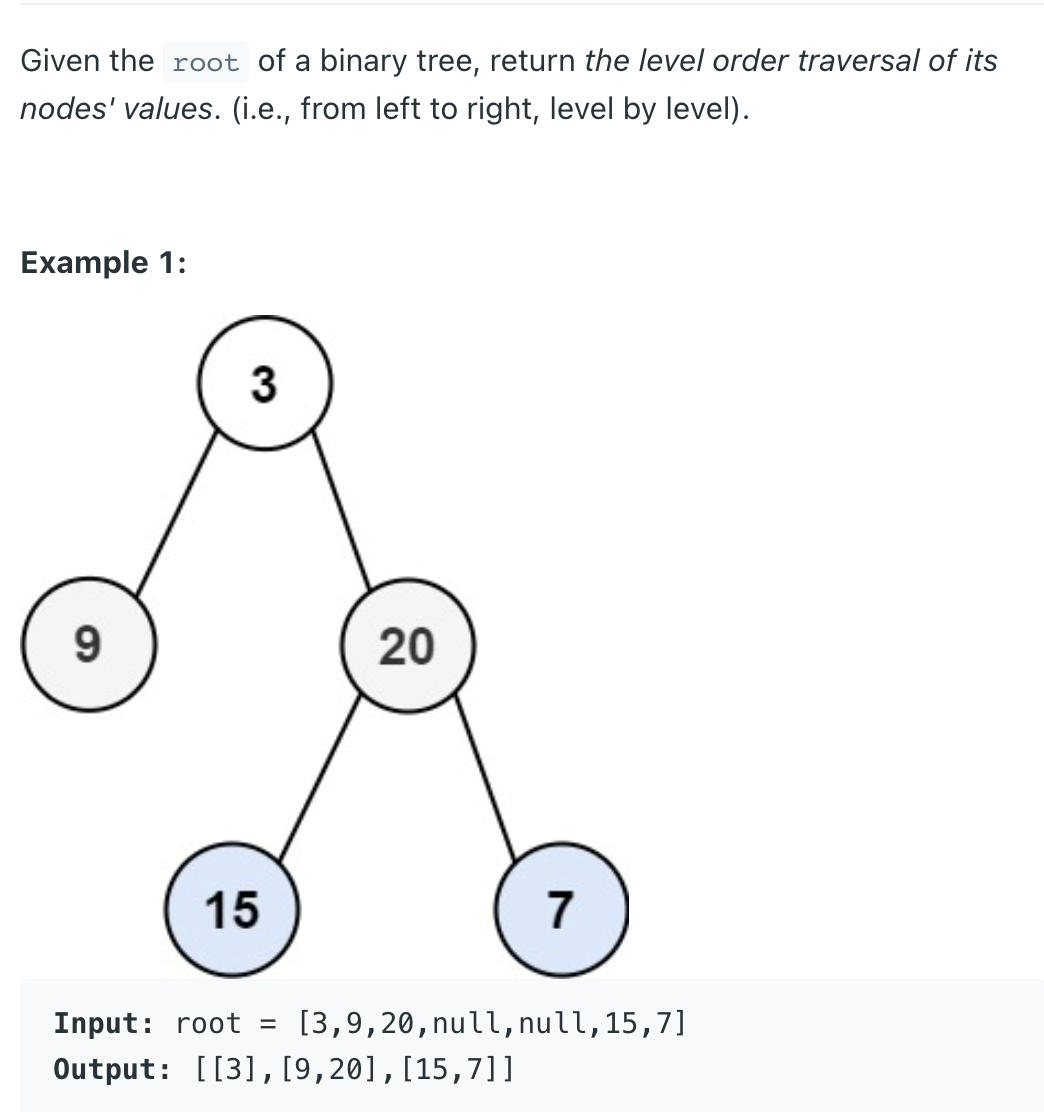
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null)
return res;
levelOrderHelper(res, root, 0);
return res;
}
public void levelOrderHelper(List<List<Integer>> res, TreeNode root, int level) {
if (root == null)
return;
List<Integer> curr;
if (level >= res.size()) {
curr = new ArrayList<>();
curr.add(root.val);
res.add(curr);
} else {
curr = res.get(level);
curr.add(root.val);
//res.add(curr); // No need to add the curr into the res, because the res.get(index) method does not remove the index element
}
levelOrderHelper(res, root.left, level + 1);
levelOrderHelper(res, root.right, level + 1);
}
class Solution {
public List<List<Integer>> levelOrderBottom(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if(root == null) return result;
Deque<TreeNode> q = new ArrayDeque<>();
q.add(root);
while(!q.isEmpty()){
int n = q.size();
List<Integer> attach = new ArrayList<>();
for(int i=0;i<n;i++){
TreeNode cur = q.poll();
attach.add(cur.val);
if(cur.left != null) q.add(cur.left);
if(cur.right != null) q.add(cur.right);
}
result.add(attach);
}
Collections.reverse(result);
return result;
}
}
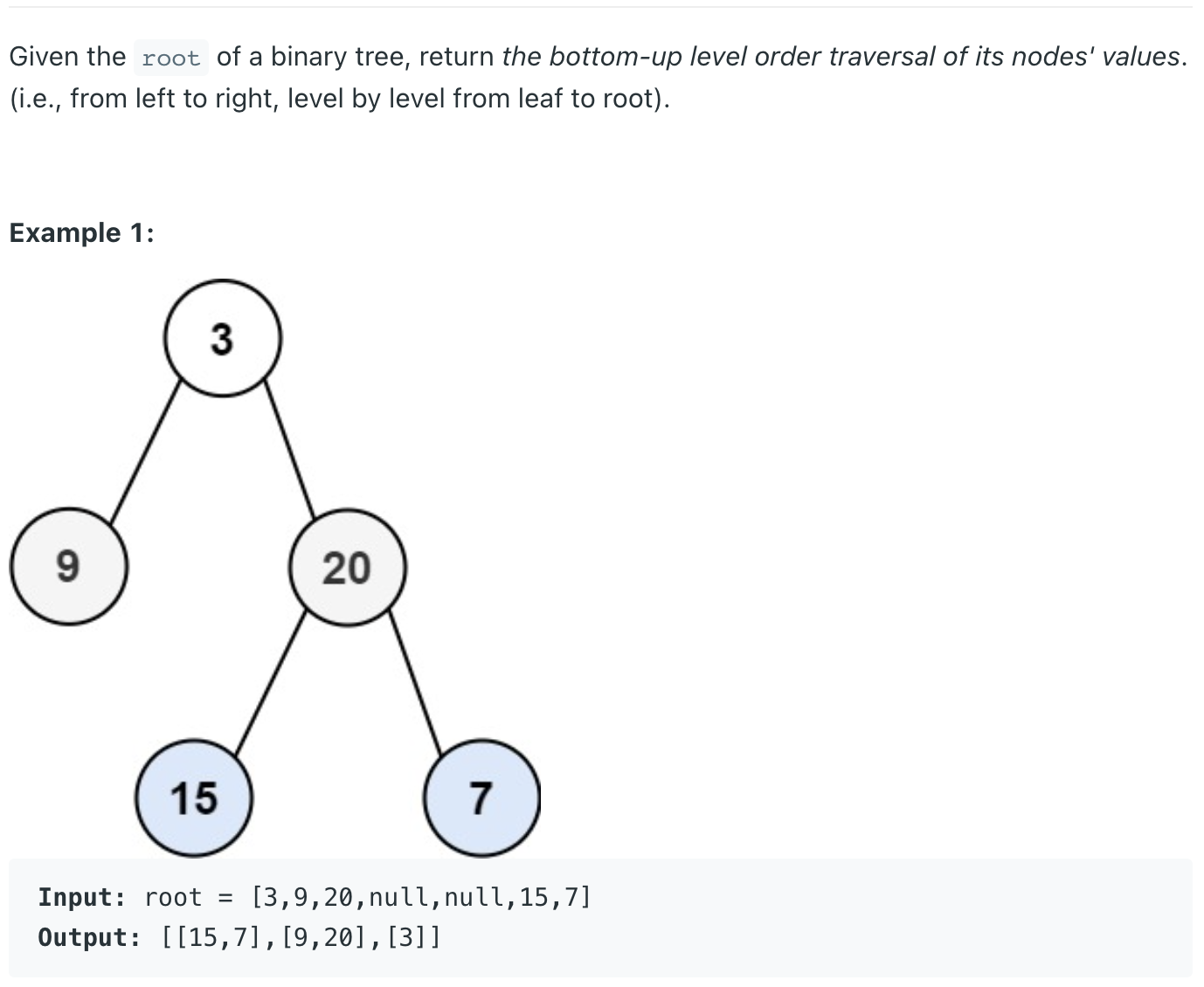
이렇게 말고도 정답을 linkedList로 생성해서 result.add(0, attach); 이런 식으로 하는 사람도 있었다. 확실히 리버스 보다 링크드 리스트 앞으로 삽입 하느것이 빠르다 속도적인 측면에서의 차이는 없었으나 제출자 들 사이에서 의 속도 차이는 많이 유의미했다.
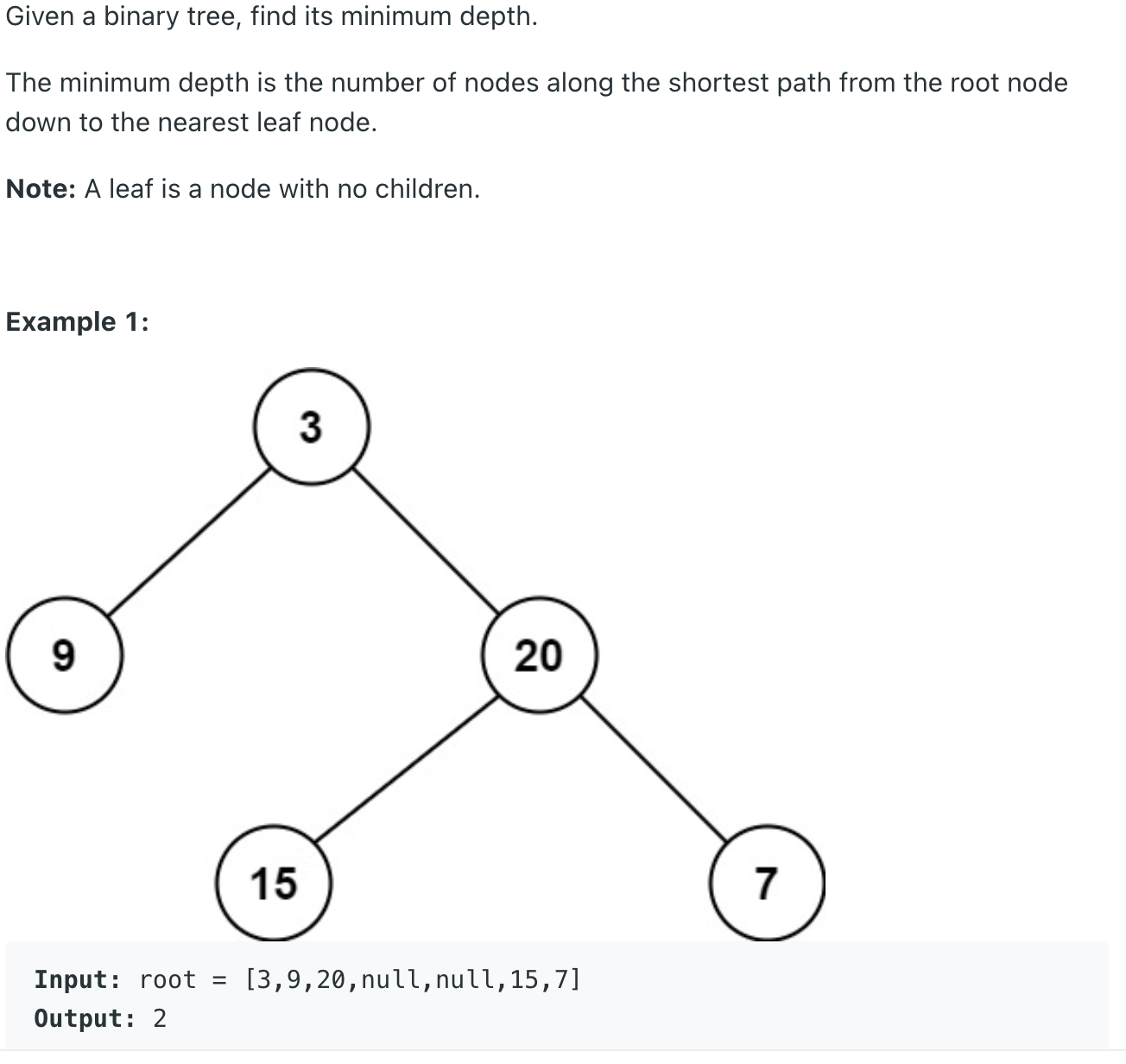
음? 이번에는 트리 깊이의 최솟값을 구하면 된다 bfs 돌다가 처음 자식들이 null 인 경우의 깊이를 반환해주면 된다.
class Solution {
public int minDepth(TreeNode root) {
if(root == null) return 0;
int d = 1;
Deque<TreeNode> q = new ArrayDeque<>();
q.offer(root);
while(!q.isEmpty()){
int n = q.size();
// for each level
for(int i=0;i<n;i++){
TreeNode node = q.poll();
if(node.left == null && node.right == null){
return d;
}
if(node.left != null){
q.offer(node.left);
}
if(node.right != null){
q.offer(node.right);
}
}
d++;
}
return d;
}
}
특별할 것 없는 코드이다. 위에 설명한 대로 최초 만난 자식 없는 노드는 리프임으로 현재 깊이를 반환해준다.
이 문제는 dfs 보다는 bfs 가 더 괜찮다고 생각한다. 왼쪽에는 노드 한 개가 있지만 오른쪽은 노드가 500 층까지 있다고 생각하면 bfs의 경우 왼쪽 노드 한 개를 탐 새하고 리턴 하지만, dfs의 경우 반대쪾 500 개 모두를 탐색해야 한다. 그래도 dfs 코드는 섹시하니깐 첨부한다.
public class Solution {
public int minDepth(TreeNode root) {
if(root == null) return 0;
int left = minDepth(root.left);
int right = minDepth(root.right);
return (left == 0 || right == 0) ? left + right + 1: Math.min(left,right) + 1;
}
}
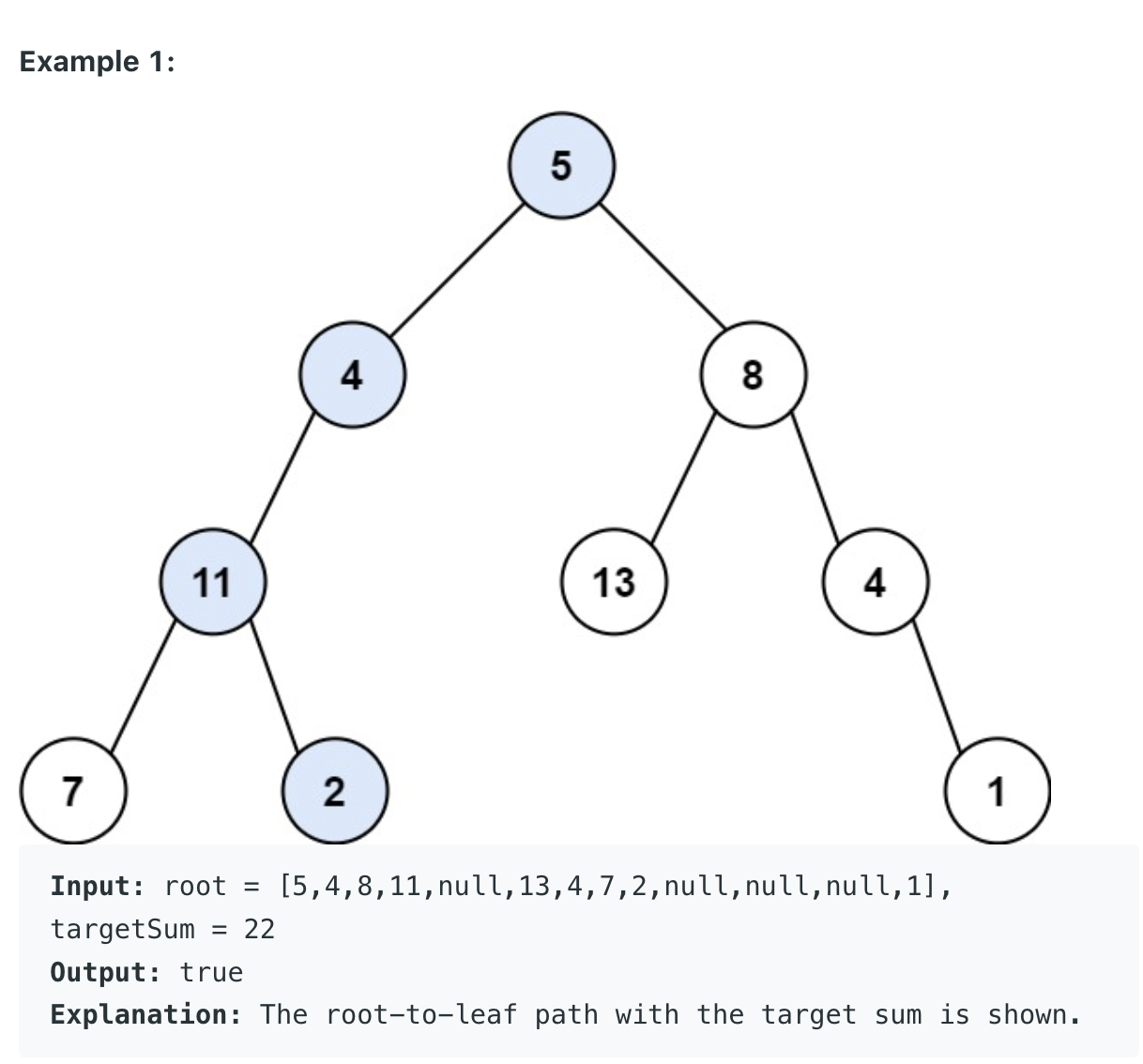
이 문제는 트리 가 주어지고 타깃 값이 주어지면 현재 시작점부터 리프까지 그중에 타겟값이 존재하냐는 문제이다. 처음 - 값의 제한상을 보지 못해서 트리의 bfs를 진행함과 동시에 가중치를 넘겨주었다 이 가중치가 타깃보다 크다면 q에 추가를 하지를 않았는데 제한사항을 보니 - 값이 있기에 위의 최적화 부분을 제외해 주었다.
최단 경로를 구하는 알고리즘 중 하나이다. 지난번 cs 네트워크 라우터 관련 검색하다가 잠깐 살펴본 내용인데 이번 기회에 흐름을 익혀보고자 글을 작성한다.
위의 그래프 에서 각 노드 간 의 최단거리를 구하는 방법 중 하나이다.
distance 의 배열이 존재하고 모두 최대 값 혹은 엄청 큰수로 초기화를 진행한다. 배열 의 수는 노드의 갯수 만큼 구성해서 계속 저장해 가며 값을 기록한다.
0번 에서 출발한다고 할시 갈수 있는경우 0-1, 0-2 이 가존재하며 배열에는 아래와 같이 기록한다.
distance = 0 | 5 | 1 | INF | INF | INF => 최초 시작점을 0 으로 대입해 시작 하며 이후 다음 노드는 거리가 가장 짧은 2번 부터 진행한다. 이렇게 진행하며 현재 진행 중인 간선의 수가 노드의 갯수-1 이된다면 진행을 멈추고 마지막 값을 리턴하면 그것 이 최단 거리가 된다.
코드로 구현해보자.
class Node{
int to;
int distnace;
public Node(int to, int distance) {
this.to = to;
this.distnace = distance;
}
}
각각 의 노드 에 대한 정보를 기록하기 위해 이너클래스 로 노드를 하나 구성해준다.
class Dijkstra{
public void dijkstra(int[][] locateInfo, int edge, int start){
ArrayList<ArrayList<Node>> graph = new ArrayList();
for(int i=0;i<edge;i++){
graph.add(new ArrayList());
}
for(int i=0;i< locateInfo.length;i++){
int from = locateInfo[i][0];
int to = locateInfo[i][1];
int distance = locateInfo[i][2];
graph.get(from).add(new Node(to,distance));
}
}
}
노드 를 담기 위한 2중 리스트를 생성 해준다. 각 첫번째 리스트 는 현재 엣지 를 의미하고 그안에 담긴 리스트 들은 갈수 있는 경로 를 생성해 더해준다.
public void dijkstra(int[][] locateInfo, int edge, int start){
ArrayList<ArrayList<Node>> graph = new ArrayList();
for(int i=0;i<edge;i++){
graph.add(new ArrayList());
}
for(int i=0;i< locateInfo.length;i++){
int from = locateInfo[i][0];
int to = locateInfo[i][1];
int distance = locateInfo[i][2];
graph.get(from).add(new Node(to,distance));
}
int[] shortest_dist = new int[edge];
Arrays.fill(shortest_dist,1,shortest_dist.length,1<<30);
PriorityQueue<Node> q = new PriorityQueue<>((x,y)->x.distnace - y.distnace);
boolean[] visit = new boolean[edge+1];
q.offer(new Node(start,0));
}
거리 들을 기록할 배열을 하나 생성해주고 , 2^31-1 이 int 의 최대값이니 그전 까지 업데이트 해주자 전에 한번 overflow 나고 나서부터는 이렇게 초기화를 진행하고 있다.
우선순위 큐를 거리가 짧은 순으로 해서 생성해주고, 마지막까지 가는데 있어 중복 계산을 피할 방문 배열을 생성해준다.
처음 시작점을 변수로 제공받기 떄문에 큐안에 시작점을 넣어주자
public void dijkstra(int[][] locateInfo, int edge, int start){
ArrayList<ArrayList<Node>> graph = new ArrayList();
for(int i=0;i<edge;i++){
graph.add(new ArrayList());
}
for(int i=0;i< locateInfo.length;i++){
int from = locateInfo[i][0];
int to = locateInfo[i][1];
int distance = locateInfo[i][2];
graph.get(from).add(new Node(to,distance));
}
int[] shortest_dist = new int[edge];
Arrays.fill(shortest_dist,1,shortest_dist.length,1<<30);
PriorityQueue<Node> q = new PriorityQueue<>((x,y)->x.distnace - y.distnace);
boolean[] visit = new boolean[edge+1];
q.offer(new Node(start,0));
while(!q.isEmpty()){
Node cur = q.poll();
if(visit[cur.to]) continue;
visit[cur.to] = true;
for (int i = 0; i < graph.get(cur.to).size(); i++) {
Node next = graph.get(cur.to).get(i);
if(visit[next.to]) continue;
if(shortest_dist[next.to] > cur.distnace+next.distnace){
shortest_dist[next.to] = cur.distnace+next.distnace;
q.offer(new Node(next.to,shortest_dist[next.to]));
}
}
}
System.out.println(Arrays.toString(shortest_dist));
}
큐 안이 비어있기 전까지 계속 반복문 을 돌려준다. 대신 모든 곳을 방문 했다면 큐 를 계속해서 뽑아오기 때문에 반복문 아래부분 까지 내려가지 않고 계속 뽑아주어 함수를 종료해준다.
현재 가려는 방향의 엣지를 받아와 그안에 들어있는 갈수있는 방향들에 대한 정보들을 뽑아와 기록 되어있는 거리와 현재 거리+다음 노드의 거리 를 이용해 최소값을 계속 업데이트 하는 방식이다. 만약 그렇게 업데이트 가 되었다면 큐에 다시 넣어주어 새로운 지점에서 시작하는 노드를 넣어준다. 2~3 번 이상 계속 노트에 손코딩 하다보니 외워버렸지만 미래에 찾고있을 나를 위해 이렇게 정리해 보았다.