엔진엑스를 사용하지 않고 에코에서 는 리버스 프록시 미들웨어를 제공해 준다. 해당 기능을 이용해서 작성해 보자.
그전에 프록시 에 대해 보다 명확하게 하고 넘어가자.
프록시 란?
프록시란? 대리라는 의미로 주로 네트워크 상에서 통신이 불가능한 두 점 사이를 통신 가능하게 만들어 주는 중계기 역할을 의미한다.
그 외에도 프록시는 보안, 로드밸런싱, 캐싱 다양한 기능을 제공한다.
먼저 그중 자주 언급되는 2가지에 대해 알아보자.
1. 로드벨런싱 : 여러 서버 사이의 트래픽을 분산시켜 서비스의 안정성과 성능을 향상한다.
예를 들어 8080 8081 이렇게 두 개의 포트로 동일한 서버가 존재하고 있다면 프로시 서버에서는 하나의 요청을 통해 어디 포트로 요청할지 특정 알고리즘을 활용해 각 서버의 트래픽 부하를 분산시켜 주는 것을 생각하면 편하다.
2. 캐싱 : 자주 요청되는 데이터 또는 특정 데이터들을 프록시 서버에 보관해 리소스를 효율적으로 사용하며 성능을 향상한다.
외부서버 와 데이터 통신을 줄여 네트워크의 병목현상을 방지하는 효과도 얻을 수 있게 된다.
(위 2가지의 기능을 본다면 어떤 특정 소프트웨어가 떠올라야 한다.)
이러한 프록시에는 2가지 종류가 있다. 여기서 보안의 목적이 나온다.
1. 포워드 프록시
포워드 프록시는 그림에서 보는것처럼 요청자,클라이언트 들은 인터넷에 직접 요청을 하는것이 아닌 프록시 서버가 요청을 받아 해당 인터넷 요청 결과를 전달해주는 것이다.
딱 봐도 저 박스 안에 갇혀있는 유저들을 관리하기 쉽다. 정해진 사이트의 요청만 가능하도록 제한하기 용이하며, 요청이 한 군데로 모여 결국 프록시 서버와 인터넷 이 통신을 하기때문에 비용절감에 탁월하다. 이에 기업환경에서 많이 사용된다.
2. 리버스 프록시
포워드 프록시와 다른점은 인터넷 과 프록시 서버의 위치가 변경되었다.
이렇게 되면 클라이언트, 유저 들은 프록시에 연결되었다는 사실을 인지할 수 없으며 마치 요청을 최종 요청을 내부망에 보는 것과 같이 느끼게 된다. 이렇게 하는 이유는 보안이 주된 이유이다.
내부망이 바로 인터넷과 통신하여도 문제는 없다 다면 내부망 혹은 내부 서비스를 제공하는 서버가 해킹당하거나, 털리는 경우 심각한 보안문제를 초래할 수 있다. 그렇기에 리버스프록시를 설정하여 위와 같은 구조를 가져가게 된다.
두 개 중 한 개를 택해서 구현할 수도 있고 두 개를 복합적으로 선택해서 구현할 수도 있으니 이분법 적인 사고에 갇히지 말자.
개념을 알게 되었으니 이제 고에서 제공하는 리버스 프록시 미들웨어 구현을 바로 가보자.
func setupProxyGroup(e *echo.Echo, path string, url *url.URL, transport http.RoundTripper) {
group := e.Group(path)
group.Use(middleware.ProxyWithConfig(middleware.ProxyConfig{
Balancer: middleware.NewRoundRobinBalancer([]*middleware.ProxyTarget{{URL: url}}),
Transport: transport,
}))
}
func main() {
flag.Parse()
cfg, err := config.Init(*configFile)
if err != nil {
fmt.Printf("config init failure file(%s) : %s\n", *configFile, err)
os.Exit(-1)
}
fmt.Println(cfg)
utils.ProcessIgnoreSignal()
e := echo.New()
e.Use(middleware.CORSWithConfig(middleware.CORSConfig{
AllowOrigins: []string{"*"},
AllowHeaders: []string{"*"},
AllowMethods: []string{"*"},
}))
e.Use(middleware.Recover())
e.Use(middleware.LoggerWithConfig(middleware.LoggerConfig{
Format: "[Proxy] ${status} ${method} ${host}${path} ${latency_human} ${time_rfc3339}" + "\n",
}))
transport := &http.Transport{
TLSClientConfig: &tls.Config{
InsecureSkipVerify: true,
},
}
/**
cms server
*/
cmsServerURL, err := url.Parse(cfg.Server.CmsServer)
if err != nil {
logrus.WithError(err).Errorf("cms server parse err %v", cfg.Server.CmsServer)
}
// 주소 생략
/**
api server
*/
apiServerURL, err := url.Parse(cfg.Server.ApiServer)
if err != nil {
logrus.WithError(err).Errorf("api server parse error %v", cfg.Server.ApiServer)
os.Exit(-1)
}
// 주소 생략
/**
chat server
*/
chatServerURL, err := url.Parse(cfg.Server.ChatServer)
if err != nil {
logrus.WithError(err).Errorf("chat server parse err %v", cfg.Server.ChatServer)
}
setupProxyGroup(e, "/chat/live/:id", chatServerURL, transport)
/**
manager server
*/
managerServerURL, err := url.Parse(cfg.Server.ManagerServer)
if err != nil {
logrus.WithError(err).Errorf("chat server parse err %v", cfg.Server.ChatServer)
}
setupProxyGroup(e, "/chat", managerServerURL, transport)
server := http.Server{
Addr: cfg.Server.Port,
Handler: e,
TLSConfig: &tls.Config{
NextProtos: []string{acme.ALPNProto},
},
}
log.Error(server.ListenAndServeTLS(cfg.Server.SSLCrt, cfg.Server.SSLKey))
}
리버스 프록시가 되어야 하기 때문에 CORS에 해당하는 모든 부분은 열어주었다. 왜? 내부서비스 가장 앞단에 위치해야 하기 때문이다.
중간에 보면 Recover와 Logger의 미들웨어를 추가적으로 사용했다.
우선 Recover는 http 프로토콜 통신간 어느 한 체인에서 패닉이 발생하더라도 리커버로 해당 패닉을 수습해 계속 서버를 유지하기 위해 작성했다. 실제 서비스에서 이러한 옵션은 버그를 양산할 수 있는 부분이 될 수 있으니 사용을 지양해야 한다. 리버스프록시 서버의 목적에 맞게 옵션을 추가해서 사용하자.
이렇게 각 해당 서비스 별로 패스를 구분 지어 그룹 단위로 셋업을 진행했다. 이중 ProxyCofig 구조체 생성간에 Balancer는 필수 값이다. 위에서 언급한 것처럼 프록시에 는 로드밸런싱 기능이 있는데 에코에서는 이를 필수 값으로 지정해 타깃으로 정한다. 작성된 코드는 오직 하나의 url을 이용하기 때문에 로드밸런싱의 기능은 전혀 활용하지 못하고 있다고 보면 된다.
Transport라는 생소한 부분이 보일 텐데 이는 Custom Tls 즉 사설 인증서를 사용하는 경우 필수 적이라고 명시되어 있다.
해당 포트 및 서버는 사설 인증을 받아 https를 테스트 용도의 목적으로 개설했기 때문에 옵션을 설정해주어야 한다.
모든 프록시는 동일한 http.TransPort를 받는데
transport := &http.Transport{
TLSClientConfig: &tls.Config{
InsecureSkipVerify: true,
},
}
저기서 InsecureSkipVerify는 기본이 false 옵션이다. true 옵션을 추가하게 된다면 crypto/tls의 패키지에서는 아무 인증서나 패스해 주는 것을 의미한다. 따라서 이는 테스트 환경에서만 적용할 것을 권장한다고 주석 처리 되어 있으니 해당 옵션은 테스트 서버에서만 사용하자.
엔진엑스를 사용 못하고, 경량화된 프록시의 역할을 하는 무언가가 필요하다면 이렇게 에코에서 제공하는 리버스 프록시 서버를 작성해 보는 것도 좋은 방법 중에 하나가 될 수 있을 것 같다.
이외에도 에코 에는 구조체, 인터페이스 별로 주석이 정말 잘 달려있다. 무조건 함수 혹은 인터페이스 타고 들어가서 구현체 확인해 보자. 구글도 알려주지 않는 것을 주석에서 알려주고 있다.
지난번 어댑터 패턴에 대해서 알아보았다. 어댑터 패턴과 유사하지만 다른 역할을 하는 패턴에 대해 정리해보고자 한다.
구조패턴 이란 것은 구조를 효율적으로 유지하면서 객체들과 클래스 들을 더 큰 구조로 조립하는 방법을 의미한다.
퍼사드 패턴 또한 이런 분류로 속하게 되는 이유에 대해 생각해 보면서 글을 작성해보고자 한다.
퍼사드 패턴 이란 ?
퍼사드는 클래스 라이브러리 같은 어떤 소프트웨어의 다른 커다란 코드 부부에 대해 간략화된 인터페이스를 제공하는 객체이다. - 퍼사드는 소프트웨어 라이브러리를 쉽게 사용할 수 있게 해 준다. 퍼사드는 공통적인 작업에 대해 간편한 메서드들을 제공해 준다. 래퍼가 특정 인터페이스를 준수해야 하며, 폴리모픽 기능을 지원해야 할 경우에는 어댑터 패턴을 쓴다. 단지 쉽고 단순 한 인터페이스를 이용하고 싶을 경우에는 퍼사드를 쓴다. - wiki 퍼사드패턴 -
퍼사드 패턴은 라이브러리에 대한, 프레임워크에 대한 또는 다른 클래스들의 복잡한 집합에 대한 단순화된 인터페이스를 제공하는 구조적인 디자인 패턴입니다. - guru -
퍼사드패턴 은 서브시스템에 있는 일련의 인터페이스를 통합 인터페이스로 묶어줍니다. 또한 고수준 인터페이스도 정의하므로 서브시스템을 더 편리하게 사용할 수 있습니다. - HeadFirst -
각 사이트 혹은 책에서 읽은 내용의 정의를 종합해 보자면 퍼사드 패턴은 무언가 묶어주 는 인터페이스 역할을 하게 되고 클라이언트는 이 인터페이스와 통신한다 정도로 이해된다. 이에 클라이언트는 오로지 퍼사드를 통해서 통신하게 되어 의존관계가 줄어든다.
왜 사용하는가?
1. 단순한 인터페이스
- 클라이언트 와 복잡한 서브시스템 사이에 단순한 인터페이스를 제공한다. 이로 인해 클라이언트 코드는 간결해지고, 사용법을 쉽게 이해할 수 있다.
2. 복잡성 감소
- 복잡한 서브시스템을 단순한 인터페이스로 감싸기 때문에, 클라이언트는 서브시스템의 내부 동작에 대해 걱정할 필요가 없다.
3. 결합도 감소
- 서브시스템과 클라이언트 사이의 결합도를 감소시킨다. 서브시스템의 내부 변경이 발생해도 퍼사드의 인터페이스를 유지하기만 하면 클라이언트는 코드를 수정하지 않아도 된다.
4. 클라이언트 편의성
- 퍼사드 패턴은 서브시스템의 기능을 논리적으로 그룹화할 수 있으며, 이는 클라이언트가 필요로 하는 기능을 쉽게 찾을 수 있게 도와준다.
퍼사드 패턴 또한 SOLID 원칙 중 개방폐쇄 원칙을 잘 지키고 있다고 볼 수 있다. 왜? 새로운 기능을 추가하거나, 기존 기능을 변경할 때 클라이언트는 코드를 수정하지 않아도 된다.
구조
말 그대로 다양한 구조체에 대해 통합해서 무언가를 한다는 느낌이 그림으로만 봐도 느껴진다.
퍼사드 패턴의 적용
- 퍼사드 패턴은 복잡한 하위 시스템에 대한 제한적이지만 간단한 인터페이스가 필요할 때 사용한다.
영화 하나 보기 위해서 퍼사드가 없다면 클라이언트에서는 watchmovie를 전부 구현하고, 각 구조체를 들고 있어야 한다. 즉 모든 구조체들과 결합하게 된다는 의미이다. 이걸 중간 인터페이스로 추상화를 시킨다면
클라이언트는 퍼사드와 만 통신을 하면 된다.
func TestFacade(t *testing.T) {
homeTheater := NewHomeTheaterFacade(
NewAmplifier(),
NewTuner(),
NewStreamingPlayer(),
NewProjector(),
NewTheaterLights(),
NewScreen(),
NewPopcornPopper(),
)
homeTheater.watchMovie("Inception")
}
Get ready to watch a movie...
[PopcornPopper] on
[PopcornPopper] pop
[TheaterLights] dim
[Screen] down
[{} Projector] on
[{} Projector] wideScreenMode
[Tuner][StreamingPlayer][Amplifier] on
[Tuner][StreamingPlayer][Amplifier] setStreamingPlayer
[Tuner][StreamingPlayer][Amplifier] setSurroundSound
[Tuner][StreamingPlayer][Amplifier] setVolume
[StreamingPlayer] on
[StreamingPlayer Inception] play
--- PASS: TestFacade (0.00s)
PASS
이런 식의 코드 구현이 된다. 막상 구현하다 보면 익숙한 느낌이 든다 왜?
우리는 함수를 구현할 때 도 이와 유사하게 작성한다. 함수 하나당 한의 기능별로 구분을 하고 그 기능을 통합으로 호출하는 함수를 만드는 경우도 있다.
우리는 알게 모르게 디자인 패턴에서 사용되는 개념들을 사용하면서 코딩을 하고 있었다 왜? 그게 더 편하고 유지보수가 편하니깐 함수가 작은 단위로 나눠지면서 재사용성을 가져가고 유지보수하기 가 편해지기 때문에 이렇게 코딩해 왔다.
아 위에서 퍼사드패턴에 대해서 설명할 때 인터페이스를 계속 말했었는데 저기서 언급한 인터페이스는 프로그래밍 언어의 인터페이스가 아닌 객체의 추상화를 의미한다. 즉 상위개념으로 캡슐화한다?라고 이해하면 될 것이다.
인터페이스 라고 해서 꼭 인터페이스 와 구조체의 구조를 가져갈 필요는 없는 것이다.
어댑터 패턴, 퍼사드 패턴, 데코레이터 패턴 뭔가 다 비슷하게 감싸고 변환하는 등의 구조적인 변환이 있어 비슷한데 정리를 하고 가자.
데코레이터 패턴 => 객체에 추가 요소를 동적으로 더할 수 있다. 데코레이터를 사용하면 서브클래스를 만들 때 보다 훨씬 유연하게 기능을 확장할 수 있다.
어댑터 패턴 => 특정 클래스 인터페이스를 클라이언트에서 요구하는 다른 인터페이스로 변환한다. 인터페이스가 호환되지 않아 같이 쓸 수 없었던 클래스를 사용할 수 있게 도와준다.
퍼사드 패턴 => 서브시스템에 있는 일련의 인터페이스를 통합 인터페이스로 묶어 준다. 또한 고수준 인터페이스도 정의하므로 서브시스템을 더 편리하게 사용할 수 있다.
지난번 구조패턴으로 데코레이터 패턴에 대해서 알아보았다, 구조패턴의 두 번째 패턴으로 어댑터 패턴을 정리해 보고 자 한다.
구조패턴 이란?
구조패턴 은 구조를 유연하고 효율적으로 유지하면서 객체들과 클래스들을 더 큰 구조로 조립하는 방법을 설명한다.
어댑터 패턴이란 ?
어댑터 패턴(Adapter pattern)은 클래스의 인터페이스를 사용자가 기대하는 다른 인터페이스로 변환하는 패턴으로 호환성 없는 인터페이스 때문에 함께 동작할 수 없는 클래스들이 함께 작동하도록 해준다. -wiki-
어댑터는 호환되지 않는 인터페이스를 가진 객체들이 협업할 수 있도록 하는 구조적 디자인 패턴입니다. -guru-
구루, 위키에서 정의하는 공통적인 목표가 있는 패턴이다.
바로 "인터페이스를 원하는 인터페이스에 맞도록 동작"에 초점이 맞춰져 있다 는 의미이다.
왜 사용하는가?
- 기존 패턴들보다 명확한 이유가 보인다. 바로 인터페이스를 통한 객체의 통신을 연결해 주는 중간다리로 생각하면 될 것 같다.
- 어댑터 패턴은 SOLID 원칙 중 특히 OCP를 잘 지키고 있다. (기존 인터페이스와 새로운 인터페이스의 연결을 위해 중간다리를 만들어주는거니깐 )
- 리스코프치환 원칙 또한 지켜지고 있다. 인터페이스 의 사용주체 "클라이언트"는 어댑터를 사용하더라도 원래 인터페이스를 사용하던 것과 동일한 방식으로 동작하며, 결과를 반환해야 한다. 프로그램의 정확성을 깨지 않으면서 하위타입의 인스턴스를 상위 타입의 객체로 치환 가능해야 한다는 리스코프 원칙이 어느 정도 반영되었다고 볼 수도 있다.
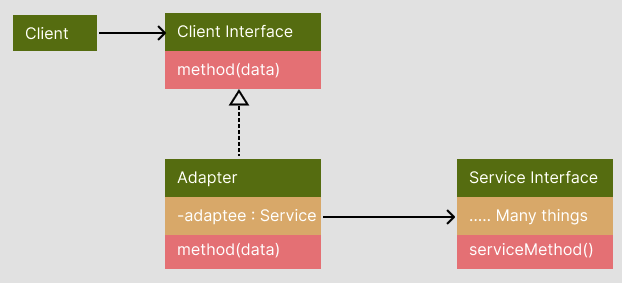
구조
왼쪽은 어댑터 패턴의 구조이고, 오른쪽은 데코레이터 패턴의 구조이다. 구조를 보게 되면 아무래도 데코레이터 도 그렇고, 어댑터도 그렇고 생성패턴? 과 는 달리 인터페이스가 아닌 구조체로 받아서 작성하게 된다.
이 부분에 대해서는 코드를 작성하면서 추가적으로 예시를 작성하고자 한다.
어댑터패턴의 적용
- 어댑터 구조체는 기존 구조체를 사용하고 싶지만 그 인터페이스가 나머지 코드와 호환되지 않을 때 사용한다.
- 이 패턴은 부모 클래스에 추가할 수 없는 어떤 공통 기능들이 없는 여러 기존 자식 클래스들을 재사용하려는 경우에 사용한다.
type PostgreSQL interface {
InsertColumn()
DeleteColumn()
UpdateColumn()
ReadColumn()
}
type PostgreSQL_V15 struct {
db string
}
func (p PostgreSQL_V15) InsertColumn() {
fmt.Println("Insert by postgresql version 15")
}
func (p PostgreSQL_V15) DeleteColumn() {
fmt.Println("Delete by posgresql version 15")
}
func (p PostgreSQL_V15) UpdateColumn() {
fmt.Println("Update by postgresql version 15")
}
func (p PostgreSQL_V15) ReadColumn() {
fmt.Println("Read by postgresql version 15")
}
var _ PostgreSQL = (*PostgreSQL_V15)(nil)
func NewPostgreSQL() PostgreSQL {
return &PostgreSQL_V15{"postgresql version 15"}
}
type MySQL interface {
InsertData()
DeleteData()
UpdateData()
ReadData()
}
type MySQL_V8 struct {
db string
}
func (m MySQL_V8) InsertData() {
fmt.Println("Insert by mysql version 8")
}
func (m MySQL_V8) DeleteData() {
fmt.Println("Delete by mysql version 8")
}
func (m MySQL_V8) UpdateData() {
fmt.Println("Update by mysql version 8")
}
func (m MySQL_V8) ReadData() {
fmt.Println("Read by mysql version 8")
}
var _ MySQL = (*MySQL_V8)(nil)
func NewMySQL() MySQL {
return &MySQL_V8{"mysql version 8"}
}
type DbBatch interface {
BatchInsert()
BatchDelete()
BatchUpdate()
BatchRead()
}
type MySQL_V8_Batch_Adapter struct {
mysql MySQL
}
func (m MySQL_V8_Batch_Adapter) BatchInsert() {
m.mysql.InsertData()
}
func (m MySQL_V8_Batch_Adapter) BatchDelete() {
m.mysql.DeleteData()
}
func (m MySQL_V8_Batch_Adapter) BatchUpdate() {
m.mysql.UpdateData()
}
func (m MySQL_V8_Batch_Adapter) BatchRead() {
m.mysql.ReadData()
}
var _ DbBatch = (*MySQL_V8_Batch_Adapter)(nil)
func NewDbBatchMySQLAdapter() DbBatch {
mysql := NewMySQL()
return &MySQL_V8_Batch_Adapter{mysql}
}
type PostgreSQL_V15_Batch_Adapter struct {
postgres PostgreSQL
}
func (p PostgreSQL_V15_Batch_Adapter) BatchInsert() {
p.postgres.InsertColumn()
}
func (p PostgreSQL_V15_Batch_Adapter) BatchDelete() {
p.postgres.DeleteColumn()
}
func (p PostgreSQL_V15_Batch_Adapter) BatchUpdate() {
p.postgres.UpdateColumn()
}
func (p PostgreSQL_V15_Batch_Adapter) BatchRead() {
p.postgres.ReadColumn()
}
var _ DbBatch = (*PostgreSQL_V15_Batch_Adapter)(nil)
func NewDbBatchPostgreSQLAdapter() DbBatch {
postgres := NewPostgreSQL()
return &PostgreSQL_V15_Batch_Adapter{postgres}
}
func Test_DB(t *testing.T) {
batch := []DbBatch{NewDbBatchMySQLAdapter(), NewDbBatchPostgreSQLAdapter()}
for _, v := range batch {
v.BatchInsert()
v.BatchDelete()
v.BatchRead()
v.BatchUpdate()
fmt.Println("----------------------------------")
}
}
=== RUN Test_DB
Insert by mysql version 8
Delete by mysql version 8
Read by mysql version 8
Update by mysql version 8
----------------------------------
Insert by postgresql version 15
Delete by posgresql version 15
Read by postgresql version 15
Update by postgresql version 15
----------------------------------
--- PASS: Test_DB (0.00s)
PostgreSQL 15 버전과, MySQL8 버전을 배치로 작업하기 위해 어댑터 패턴을 적용해 클라이언트에서는 DbBatch 만 사용하고 있으면 내부구현의 수정이 어떻게 변하던지 동일한 결과를 얻게 된다.
말도 안 되지만 여기서 만약 PostgreSQL 13 버전, MySQL 5 버전 등의 버전들이 필요하게 되고 이 구조체들은 서로 다른 인터페이스를 따르고 있다면? DbBatch에 맞는 새로운 구조체를 생성해서 각각 필드값을 주입받아 해당 함수를 호출시켜 주면 되는 것이다.
데코레이터 패턴과 뭔가 느낌이 비슷하지 않은가? 정리를 해보자.
- 데코레이터 패턴 은 기존 객체에 새로운 기능을 동적으로 추가할 수 있도록 설계된 패턴이다. 객체의 데코레이션을 담당하는 별도의 데코레이터 객체를 만들어, 기본 객체에 새로운 행동을 추가하거나 수정한다. 이에 객체를 확정하거나 변경할 수 있다.
- 어댑터패턴 은 한 클래스의 인터페이스를 클라이언트가 사용하고자 하는 다른 인터페이스로 변환하는 패턴이다.
두 패턴 모두 특징이 하나 있다.
기존 코드를 건드리지 않고도 확장하거나 변경하는데 유용하다. 이게 제일 핵심인 것 같다. 다만 사용의 목적 이 상당히 다를 뿐이지만 이래서 디자인패턴은 공부를 하면 할수록 원점으로 돌아가는 나 자신이 느껴진다.
행동패턴 은 지난번 옵서버 패턴을 정리하면서 작성했다 "객체의 통신"에 목적과 의미를 둔 패턴이라고 생각하면 되겠다.
커맨드 패턴이란 ?
요청을 객체의 형태로 캡슐화하여 사용자가 보낸 요청을 나중에 이용할 수 있도록 메서드 이름, 매게 개변수 등 요청에 필요한 정보를 저장 또는 로깅,취소 할 수 있게 하는 패턴이다. -나무위키-
요청에 대한 모든 정보가 포함된 독립실행형 객체로 변환하는 행동 디자인 패턴이다. 이 변환은 다양한 요청들이 있는 메서드들을 인수화 할수 있도록 하며, 요청의 실행을 지연 또는 대기열에 넣을 수 있도록 하고, 또 실행 쉬 초할 수 있는 작업을 지원할 수 있도록 합니다. - 구루-
커맨드라는 추상회된 요청을 이용하는 방식에서 유래되었다. 커맨드 패턴은 요청 자체를 객체로 캡슐화하고, 호출자와 수신자를 분리한다. 이렇게 하면 호출자는 수신자의 인터페이스를 알 필요 없이 커맨드를 수행할 수 있다. 또한, 이런 방식은 다양한 요청, 큐 또는 로그요청, 그리고 가능한 경우에는 요청의 취소도 지원할 수 있다.
지난 패턴들과 동일하게 하나의 인터페이스 추상화를 두고 어떻게 실행하는가에 목적을 두고 있다. 정의에서 보다시피 여러 개의 커맨드를 받아 수행할 수 있다고 하는데 "공통된 인터페이스를 구현하기 때문에 가능하다."
언제 사용해야 하는가?
1. 호출자와 수신자의 분리
- 호출자가 요청을 수행하는 객체나 그 방법에 대해 알 필요가 없는 경우
- 웹사이트의 사용자 요청을 처리하는 시스템 => 각 요청을 커맨드 객체로 캡슐화해서 처리 가능
- 사용자는 실제 요청이 어떻게 처리되는지 알 필요가 없다.
2. 요청 매개변수화
- 요청을 수행하는 방법을 매개변수화 하려는 경우 커맨드 패턴이 유용하다. 요청 선택 또는 사용자 입력 등을 캡슐화하면 호출하는 시점에 서 다른 매개변수를 사용하여 요청을 수행할 수 있다.
- 사용자 인터페이스의 버튼, 각 버튼을 누르면 특정 작업을 수행할 수 있도록 설정
- 커맨드 객체는 특정 작업을 캡슐화하고 있다.
3. 요청 저장 및 로깅
-커맨드 패턴은 요청을 캡슐화하여 저장하고 로깅하는 것을 가능하게 한다.
- DB의 트랜잭션을 예로 들 수 있다. 각 트랜잭션은 수행되어야 할 작업의 목록을 가질 수 있다. 이 목록을 통해 트랜잭션의 성공여부를 확인할 수 있다.
4. 취소 및 되돌리기 기능
- 커맨드 자신의 undo 메서드를 구현해, 실행취소의 작업도 손쉽게 가능하다.
- 텍스트 에디터 의 undo 기능 사용자가 작성한 텍스트는 undo를 통해 원래 작업과 반대작업을 모두 알고 있기 때문에 가능하다.
기본적인 구조
1구루 출처
1번의 인보커 발송자는 요청들의 시작점을 나타낸다. 어떠한 커맨드가 설정될지 혹은 어떻게 execute를 할지를 나타내고, 인보커에서 List 형태로 관리되기도 한다.
2번의 커맨드는 구상 커맨드 가 구현해야 할 공통 함수를 명명한다. 보는 바와 같이 통상 1 나의 메서드 만을 표기한다.
3번의 구상 커맨드 들은 excute에서 비즈니스 로직을 수행해 준다.
4번의 수신자는 비즈니스 로직이 포함되어 있으며 "실제 비즈니스 로직 수행을 담당하고 있다"
1. 기본 설정은 다음과 같으며 http://localhost:8080/test 요청과 응답 결과이다.
(* 루트 권한이 없는 상태에서 설정하는 방법을 베이스로 합니다.)
2. 에코에서 제공하는 autoSSL 사용하기 (실패)
ssl 인증과 같은 과정을 거치지 않고 에코에서 제공하는 단순한 방법을 활용해서 작성하고자 했다.
func main() {
e := echo.New()
e.GET("/test", func(c echo.Context) error {
return c.JSON(200, struct {
Name string `json:"name"`
Message string `json:"message"`
}{"testing", "From Server !"})
})
go func() {
log.Error(e.StartAutoTLS(":8081"))
}()
log.Error(e.Start(":8080"))
}
기존 8080 은 http 요청으로 띄우고 https는 8081로 띄우고 싶었다. 기존 http 요청으로 사용하던 api들이 있을 수 있다는 생각에 위와 같이 작성
포스트맨 응답 Error: write EPROTO 4818108888:error:10000438:SSL routines:OPENSSL_internal:TLSV1_ALERT_INTERNAL_ERROR:../../../../src/third_party/boringssl/src/ssl/tls_record.cc:594:SSL alert number 80
1. 인증서와 키 파일이 올바른지 확인하기: 인증서와 키 파일이 올바르게 생성되었고, 파일 경로와 이름이 올바르게 지정되었는지 확인하세요. 또한, 인증서가 CA에 의해 서명되었다면, 모든 중간 인증서가 올바르게 체인에 포함되어 있는지 확인해야 합니다. 2. SSL/TLS 설정이 올바른지 확인하기: 서버와 클라이언트가 모두 지원하는 SSL/TLS 버전을 사용하고 있는지 확인해야 합니다. 예를 들어, 클라이언트가 TLSv1.2만 지원하는데 서버가 TLSv1.3만 지원한다면, 이러한 종류의 오류가 발생할 수 있습니다. 3. 클라이언트의 이슈가 아닌지 확인하기: 오류가 서버의 문제가 아니라 클라이언트의 문제일 수도 있습니다. 다른 클라이언트에서 같은 요청을 시도해 보고, 같은 문제가 발생하는지 확인하세요. 4. 로깅을 통해 추가적인 정보 수집: Go의 http 패키지는 기본적으로 SSL/TLS 에러에 대한 많은 정보를 제공하지 않습니다. 따라서 net/http 패키지의 httptrace 패키지를 사용하여 추가적인 디버깅 정보를 수집하거나, OpenSSL의 s_client 도구를 사용하여 SSL/TLS 핸드셰이크를 수동으로 시도해 볼 수 있습니다.
검색 결과 위와 같은 방식의 검증이 필요한 것으로 보인다. AutoSSL 함수 호출을 열어보면 letsentcrypt.org로부터 인증서를 자동으로 받아와 세팅을 해준다.
우리의 리눅스 서버에 해당 주소의 권한이 없어서 인증서 발급이 명확하게 되지 않아 실패한 것으로 보인다.
구조패턴 은 구조를 유연하고 효율적으로 유지하면서 객체들과 클래스들을 더 큰 구조로 조립하는 방법을 설명한다.
그중 데코레이터 패턴에 대해 학습해보고자 한다.
데코레이터 패턴 이란?
데코레이터 패턴 이란 주어진 상황 및 용도에 따라 어떤 객체에 책임을 덧붙이는 패턴으로, 기능 확장이 필요할 때 서브클래싱 대신 쓸 수 있는 유연한 대안이 될 수 있다. - 위키
데코레이터는 객체들을 새로운 행동들을 포함한 특수 래퍼 객체들 내에 넣어서 위 행동들을 해당 객체들에 연결시키는 구조적 디자인 패턴이다.
데코레이터 패턴으로 객체에 추가 요소를 동적으로 더할 수 있으며, 데코레이터를 사용하면 서브클래스를 만들 때 보다 유연하게 기능을 확장할 수 있다.
데코레이터 말 그대로 장식에 대해 생각하면 된다.
왜 사용하는가?
코드의 유연성, 확장성, 재사용성을 높이고 객체 지향 설계원칙을 준수하기 위해 사용된다.
객체의 동적인 기능 확정과 코드의 재사용성, 유연성을 동시에 제공하기 위해 사용된다.
객체지향 설계원칙을 따르고 있으며, 객체 간의 결합도를 낮추고 코드의 유지보수성을 향상한다.
구조
구루 에서 제공되는 구조,
컴포넌트 즉 구현되어야 할 매개체를 인터페이스로 명시하고, 해당 인터페이스를 구현하는 객체 그리고 데코레이터는 인터페이스와 동일한 함수를 구현하게 해 인터페이스 호출이 가능하도록 작성한다.
이렇게 작성된 구조체에 함수들은 주입받은 객체를 호출하고 본인을 호출하면 마치 체이닝 걸린 것처럼 연속적으로 호출되게 된다.
코드로 보면 보다 이해하기 쉽다.
type beverage interface {
cost() float32
getDescription() string
}
type HouseBlend struct {
description string
}
func (h *HouseBlend) cost() float32 {
return 0.89
}
func (h *HouseBlend) getDescription() string {
return h.description
}
type DarkRost struct {
description string
}
func (d *DarkRost) cost() float32 {
return 1.32
}
func (d *DarkRost) getDescription() string {
return d.description
}
type Milk struct {
b beverage
}
func (m *Milk) cost() float32 {
return m.b.cost() + 12.3
}
func (m *Milk) getDescription() string {
return m.b.getDescription() + " milk"
}
type Whip struct {
b beverage
}
func (w *Whip) cost() float32 {
return w.b.cost() + 15.5
}
func (w *Whip) getDescription() string {
return w.b.getDescription() + " whip"
}
func StartHead() {
//case 1
a := &HouseBlend{"house coffee"}
b := &Milk{a}
c := &Whip{b}
fmt.Println(c.cost(), c.getDescription())
//case2
var B beverage
B = &HouseBlend{"house"}
B = &Milk{B}
B = &Whip{B}
fmt.Println(B.cost())
}
음료 인터페이스가 있고, 기존 구현체인 HouseBlend, DarkLost 가 존재하고 있으며 데코레이터로 우유와 휘핑 이 있다. 이렇게 되면 데코레이터의 구현체는 주입받은 인터페이스를 이용해 호출하고 데코레이터에서 하고 싶은 함수를 호출하면 된다. 이렇게 기존함수를 호출 함에 따라 마치 연쇄적으로 함수가 동작하는듯한 효과를 가져온다.
실행의 결괏값은 아래와 같다.
- 28.69 house coffee milk whip
하우스블랜드 0.89 => 우유 12.3 => 휘핑 15.5 가 차례대로 호출되며 28.69 가 나오게 된다.
순차적으로 실행되는 듯한 느낌이 마치 장식을 해주는 것과 같은 것이 데코레이터패턴 의 이름은 정말 잘 지은 것 같다.
저위에 작성된 클라이언트 코드에서는 case1과 case2로 나누어서 사용한다. 보면 1번의 경우 하나씩 스택을 쌓아가는 반면
2번 케이스는 인터페이스하나로 받아가면서 사용한다.
이렇게 됐을 때 2번의 경우로 작성한다면 다형성을 적용하여 보다 폭넓게 사용가능하다.
고 언어에서 활용되는 기본 패키지 둘 중에 데코레이터 패턴이 적용된 것을 살펴보면
compress 패키지 에는 gzip, flate, zip 등의 패키지에서 io.Reader io.Writer 인터페이스를 구현해 데이터 압축 기능을 추가하는