5장은 추후 정리해서 올리고자 한다.
"동시성을 지원하는 언어의 장점" , OS 스레드 의 다중화를 위해 고 컴파일러는 "작업 가로채기" 전략을 사용한다 (work-strealing)
작업 가로채기 전략에 대해 알아보자.
1. 직관전인 스케쥴링 방법
공정한 스케쥴링을 상식적으로 한번 적용해 보자. 사용가능한 프로세스에 작업들을 나누어서 할당한다. 가장 이상적이고 직관적인 방식이다.
수행하는 프로세스 가 n 개 와 x 의 작업이 있다면 각 프로세스는 x/n 만큼 할당해서 작업을 수행하면 된다.
Go의 동시성 전략은 "fork-join 방식이다."

fork-join 모델 은 단순 어느 시점에서 분기가 나누어지며 미래의 특정 어느 합류지점이 생겨 메인 작업에 합류하는 것을 의미한다. 이러한 모델이 사용된다면 작업들이 서로 의존적일 확률이 매우 높아지게 되고 위에서 제시한 공정한 스케쥴링 방식에는 상당한 문제점이 발생된다.
P1, P2의 프로세스가 존재하고 해당 프로세스에서 각각 작업 a, b, c, d를 한다고 가정해 보자.
| 시간 | P1 | P2 |
| a | b | |
| n | (대기) | b |
| n+k | (대기) | c |
| n+k+m | d | 대기 |
이렇게 대기하는 시간이 생각보다 많이 발생하게 된다. 이를 해결하기 위해 fifo 대기열을 적용해서 중앙 집중식으로 구성해서 본인이 가능할 때 작업을 빼가는 방식을 적용하는 것이다.
2. 중앙 집중식 대기열
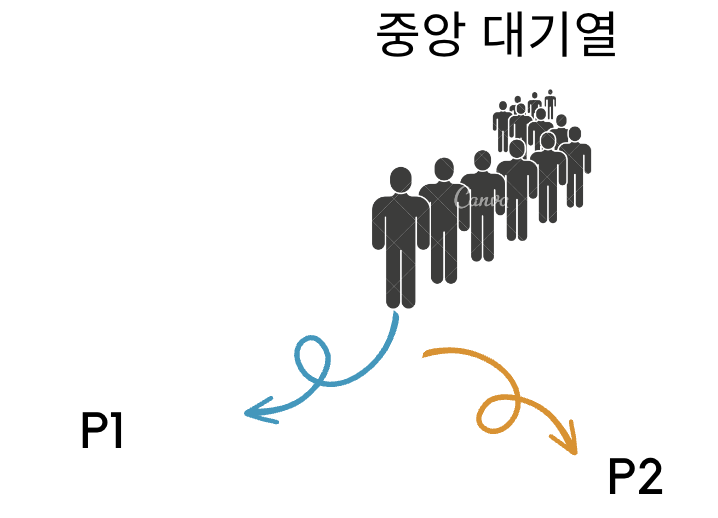
각 프로세스는 처리용량이 허용될 때 대기열에서 작업을 꺼내오고 그렇지 않으면? 조인에서 대기하고 있는다. 이는 1에서 제공하는 단순한 작업을 나누는 것보다는 나은 방법을 제공해 준다.
하나 이에 대해 문제점이 다시 존재한다. 중앙대기열이라는 임계지점을 계속 들락날락해야 하기 때문에 이에 해당하는 비용이 든다.
뿐만 아니라 캐시의 지역성에도 문제가 발생해 캐시 미스가 자주 발생할 수 있는 가능성이 농후해진다.
3. 작업 대기열을 분산시키는 방법 - 작업 가로채기
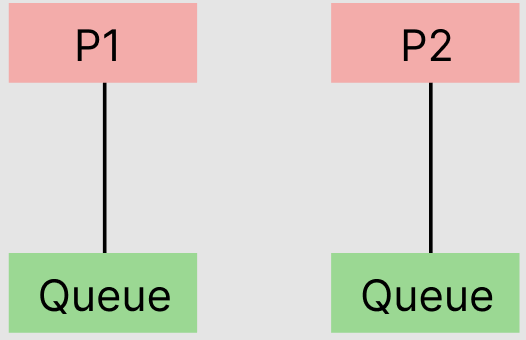
위와 같이 프로세스가 자체적으로 큐를 가지는데 해당 큐는 dequeue 성질을 가지고 있다.
고의 런타임은 포크조인 모델 방식을 따른다. 따라서 포크가 발생되는 지점이 생긴다면? 해당 스레드와 관련된 데큐의 끝 즉 꼬리에 추가된다.
이후 대기 중인 스레드가 작업을 가로채기를 할 때는 아래와 같은 규칙을 따르게 된다.
1. 스레드가 현재 처리할 작업이 없을 때 다른 스레드의 데큐에서 작업을 가로챈다.
2. 대기 중인 스레드는 주로 다른 스레드 데큐의 앞쪽(머리)에서 작업을 가로챈다.
스레드의 데큐 양쪽 이 모두 비어있는 경우
1. 조인을 지연시킨다.
- 지연을 시킴에 따라 2번 즉 다른 스레드의 데큐 앞쪽을 가로챌 수 있다.
- 합류에 대한 오버헤드를 최소화하기 위해 조인을 지연시킨다.
2. 임의의 스레드 데큐의 앞쪽 작업을 가로챈다.
코드로 표현해 보자.
func Test_runtime_go_01(t *testing.T) {
var fib func(n int) <-chan int
fib = func(n int) <-chan int {
result := make(chan int)
go func() {
defer close(result)
if n <= 2 {
result <- 1
return
}
result <- <-fib(n-1) + <-fib(n-2)
}()
return result
}
fmt.Printf("fib(4) result : %d ", <-fib(4))
}이 프로그램이 두 개의 단일코어 가 존재하는 가상머신에서 돌아간다고 가정해 보자.
프로세스 1에 대해 T1, 프로세스 2에 대해 T2를 할당한다고 가정해 보자.
| T1 호출스택 | T1작업데큐 | T2 호출스택 | T2작업데큐 |
| main 고루틴 | |||
| main 고루틴 | fib(4) | ||
| main 고루틴 합류지점 fib(4) -> 가로채기 성공 |
|||
| main 고루틴 합류지점 fib(4) -> 가로채기 성공 |
fib(3) fib(2) |
||
| main 고루틴 합류지점 fib(4) -> 가로채기 성공 |
fib(2) | fib(3) | |
| main 고루틴 합류지점 fib(4) -> 합류지점 fib(2) -> return 1 |
fib(3) | fib(1) |
|
| main 고루틴 합류지점 fib(4) -> 합류지점 fib(2) from t2 -> return 1 |
fib(3) -> 합류지점 fib(1) -> return 1 |
||
| main 고루틴 합류지점 fib(4) -> 합류지점 |
return 2 | ||
| main 고루틴 합류지점 fib(4) -> return 3 |
|||
| return 3 |
서로의 스택에서 합류지점이 발생할 때 각각의 데큐에서 꺼내가는 것이 핵심 포인트이다.
4. 작업-연속 가로채기
고에서는 위에서 제시되는 일반적인 가로채기 알고리즘이 아닌 연속 가로채기 알고리즘을 구현하고 있다.
위에서 제시된 방법은 스레드가 쉬지 않고 돌아가는 장점이 있다 다만 지속적인 합류의 지점이 발생해 조인을 위한 지연이 발생된다.
이 문제를 적절하게 해결하기 위해 연속 가로채기 알고리즘을 적용한다.
연속 가로채기 란
기본적으로 가로채기의 개념을 확장한 내용이다. 하나의 작업이 아닌 연속 부분을 가로채는 것이다.
여기서 연속이란?
포크 조인 모델 에는 2가지 옵션 작업, 연속의 개념이 존재한다.
작업 : 포크과정에서 분리되어 병렬로 실행되는 단위, 독립적으로 수행되는 특징
연속: 작업이 끝나고 수행되어야 하는 추가적인 단계나 계산을 의미 "두 하위 작업의 결과를 합쳐서 최종결과를 얻는 과정"
위와 동일한 작업을 표로 다시 한번 알아보자.
| T1 호출스택 | T1 작업데큐 | T2 호출 스택 | T2 작업데큐 |
| main | |||
| fib(4) | main 연속 | ||
| fib(4) | main 연속(T1 작업데큐 가로챔) | ||
| fib(3) | fib(4) 연속 | ||
| fib(3) | main 연속 대기 fib(4) 연속 (T1 작업데큐 가로챔) |
||
| fib(2) | fib(3) 연속 | main 연속 대기 fib(2) (fib -2 두번째 연산) |
fib4 연속 |
| return 1 | main 연속 대기 return 1 |
||
| return 1 + fib(1) | main 연속 대기 fib4 연속 |
||
| return 2 | main 연속 fib4 연속 |
||
| main 연속 return 3 (T1의 결과 t2 의결과) |
|||
| main(3) |
이렇게 변경된 작업 가로채기는 T1의 호출스택을 보면 마치 함수의 콜스택 처럼 되어 있다 T1의 콜체인은
fib(3) fib(2) fib(1) 이 되는 방식을 주목해서 보면 되겠다.
이렇게 변경된 작업가로채기 에는 연속되어 있기에 실힁 순서가 보장되며, 합류지점의 지연이 없다는 장점이 존재한다.
기존 가로채기에서는 호출스택, 작업 중인 스레드의 지연된 조인 횟수 가 연속 가로채기보다 많이 존재한다.
해당장의 실제 페이지는 상당히 적지만 너무 추상적인 내용들이라 수십 번을 읽어보아야만 했다.
고 루틴이 작업 가로채기 방식을 적용하면서도 스레드 간의 합류 비용 즉 조인의 지연을 없애기 위해 확장한 개념 연속된 가로채기와
왜 다른 언어에서는 할 수 없는지(go 의 컴파일러 때문에 가능함). 등에 대해 알 수 있었다.
위에 제공된 모든 혜택들을 우리는 고퍼이기에 go keyword를 통해 가장 효율적인 방식으로 작업이 자동으로 스케쥴링된다.
'Go > 고루틴' 카테고리의 다른 글
| 고루틴은 어떻게 동작하는가 (1) | 2023.11.16 |
|---|---|
| 고루틴 메모리 누수 - 프로파일링 (0) | 2023.08.24 |
| [Concurrency in Go] 4장 Go의 동시성 패턴 -4 (0) | 2023.06.25 |
| [Concurrency in Go] 4장 Go의 동시성 패턴 -3 (0) | 2023.06.18 |
| [Concurrency in Go] 4장 Go의 동시성 패턴 -2 (2) | 2023.06.12 |