고루틴과 OS의 관계가 궁금해 작성한 글입니다.
고 런타임에 대해 지난번 남긴 글을 읽고 온다면 보다 도움이 더욱 될 것이다.
[Concurrency in Go] 6장 고루틴과 Go 런타임
5장은 추후 정리해서 올리고자 한다. "동시성을 지원하는 언어의 장점" , OS 스레드 의 다중화를 위해 고 컴파일러는 "작업 가로채기" 전략을 사용한다 (work-strealing) 작업 가로채기 전략에 대해 알
guiwoo.tistory.com
1. 일반적인 OS-프로 스세 -스레드 와 CPU는 어떻게 동작하는가?
우선 용어를 간략하게 정의를 해보자 (wiki)
CPU : 컴퓨터 시스템을 통제하고 프로그램의 연산을 실행-처리하는 가장 핵심적인 컴퓨터의 제어 장치, 혹은 그 기능을 내장한 칩이다.
OS : 운영체제의 약자로 사용자의 하드웨어, 시스템 리소스를 제어하고 프로그램에 대한 일반적 서비스를 지원하는 시스템 소프트웨어이다. (윈도, 맥 OS X, 리눅스, BSD, 유닉스 등)
Process : 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 말한다. 종종 스케줄링의 대상이 되는 작업이라는 용어와 거의 같은 의미로 사용된다.
Thread : 프로세스에서 실행되는 흐름의 단위를 말하며 다시 말해 프로세스 내에서 실제로 작업을 수행하는 주체를 의미한다.

프로세스는 실행과 즉시 스레드가 생성되는데 이 최초의 스레드를 메인스레드라고 부른다.
운영체제는 프로세스에 상관없이 생성된 스레드에 대해 프로세서 즉 CPU에 예약하는 형태의 구조를 가지고 있다.
2. 멀티스레드 n:m
고 루틴을 사용하는 목적이 무엇인가? 효율적으로 병렬성 및 동시성을 구현하기 위해서이다.
다시 말해 멀티스레드 프로그래밍을 더 편리하고 효율적으로 하기 위해서 사용된다.
그중 멀티스레드의 모델 중 하나인 n:m 모델에 대해서 알아보자.
고 루틴 동작방식과 상당히 유사하다.

커널영역 또한 멀티스레드로 동작한다.
장치관리, 메모리관리 또는 인터럽트 처리 등등 위의 그림처럼 유저 또한 스레드를 여러 개 생성할 수 있는데
유저스레드 와 커널스레드는 1:1, 1:n, n:m의 모델에 의해서 관리되는데 우리는 그중
n:m 모델에 대해서 알아보아야 한다.
커널 스레드와 동일한 숫자 혹은 그이 하의 사용자 스레드가 매칭되는 관계를 n:m 관계라고 한다.
이때 중간에 LWP라는 경량프로세스 가 존재해 하나의 커널스레드에 다량의 유저스레드를 해결할 수 있다.
1:1로 커널 스레드와 유저스레드가 매칭되면 인터럽트, 블로킹이 발생되면 프로세스 자체가 컨택스트 스위칭이 되어버리고 만다.
해당 문제를 해결하기 위해 하나의 커널스레드에 다량의 유저스레드를 이어 붙여 유저스레드 안에서 컨택스트 스위칭이 발생하게 만들어 os까지 올라가지 않도록 하기 위해 경량 프로세스라는 의미가 붙는다.
이렇게 된다면 커널은 쉼 없이 유저 스레드와 맵핑되어 프로세스는 블로킹될 필요가 없이 사용되는 것이다.
여러 유저스레드가 병렬성을 가지고 실행될 수 있다.
고 루틴도 유사하게 진행된다 다만 lwp는 os 커널에서 관리하고, 고 루틴은 고 런타임 스케줄러에 의해서 관리된다.
여기서 고 루틴의 GMP 모델에 대해 알아보자.
G(Go-Routine) : 고 루틴을 의미한다.
M(Machine) : OS의 스레드 즉 커널스레드를 의미한다. Go에서는 최대 10k를 지원하지만 일반적으로 OS는 이런 많은 스레드를 지원하지 않는다.
P(Processor) : 고 루틴의 논리프로세스 또는 가상 프로세스 이해하면 된다. 해당 P의 숫자는 runtime의 GOMAXPROCS 설정으로 원하는 만큼 설정가능하다.
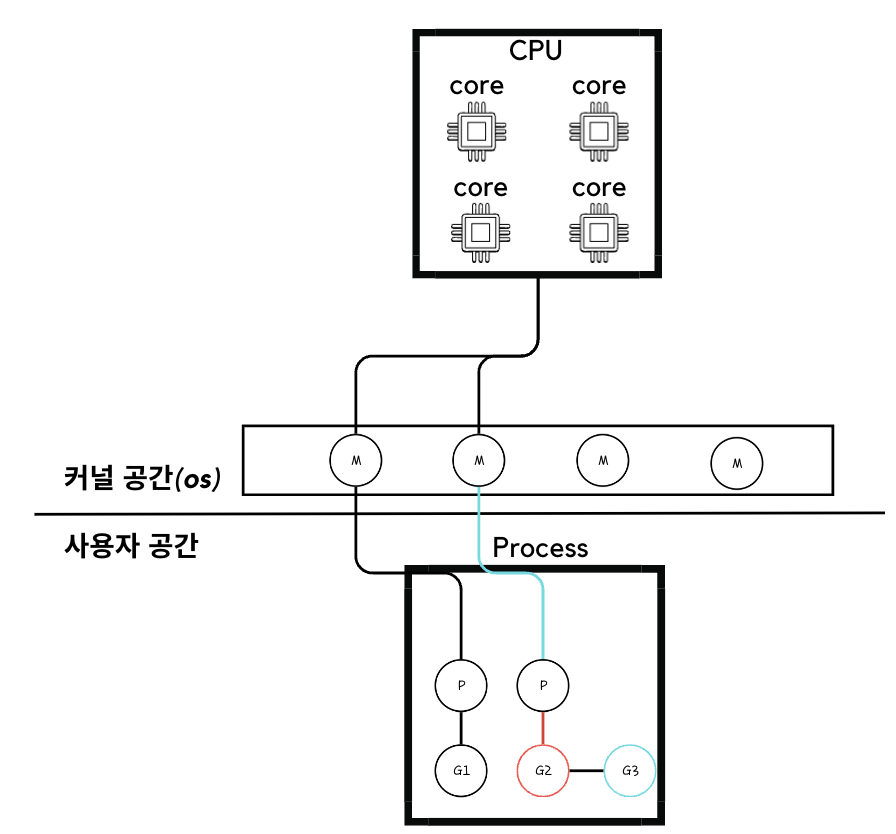
GMP 모델을 적용한 예이다.
하나의 P는 고 루틴을 실행할 수 있고 해당 루틴은 커널스레드에 할당되어 병렬적으로 실행될 수 있다.
여기서 GMP모델의 특징이 나오는데 G2의 경우 시스템호출이 발생되었다고 가정해 보자.
그렇게 되면 G2의 대기열 고 루틴인 G3이 해당 P를 가져가게되고 G2는 블로킹의 응답이 올떄가지 대기하게되는 고루틴 스위칭이 발생한다.
어떤 논리프로세스에 누가 스케줄되어 실행될지는 고 런타임 스케줄러가 결정한다.
LWP 경량 프로세스
- OS에 의해서 관리되며 n:m의 모델로 적용되어 효율적으로 코어를 사용할 수 있다.
고 루틴
- 고 런타임 스케줄러에 의해서 관리되며 논리프로세스와 고 루틴의 n:m 관계가 적용되어 효율적으로 프로세스의 자원을 사용할 수 있다.
일반적인 프로그래밍 언어의 스레드는 G2 즉 블로킹이 발생된다면 유후 스레드를 하나 가져와서 G3를 실행하게 된다.
다시 말해 스레드를 생성한다.
그러나 고 루틴은 동일 스레드를 사용하고 논리프로세스 내에서 스위칭이 발생되기 때문에 스레드를 재사용하기 때문에 즉 블로킹이 최소화 가 되어 동시성 프로그래밍의 효율이 증가한다.
코드를 통해 고 루틴과 스레드의 관계에 대해서 알아보자.
파일을 시스템 호출로 읽어와서 작성하는 로직을 써보자.
func systemCall() {
fmt.Println("system call ")
file, _ := syscall.Open("./atask_user.log", syscall.O_RDONLY, uint32(0666))
defer syscall.Close(file) // 파일 닫기 (defer를 사용하여 함수 종료 시 닫히도록 함)
// 파일 읽기
const bufferSize = 1024
buf := make([]byte, bufferSize)
for {
// 파일에서 데이터 읽기
n, err := syscall.Read(file, buf)
if err != nil {
fmt.Println("Error reading file:", err)
break
}
// 더 이상 읽을 데이터가 없으면 종료
if n == 0 {
break
}
// 읽은 데이터 출력 또는 원하는 작업 수행
fmt.Print(string(buf[:n]))
}
fmt.Println("system call done")
}
func main() {
var wg sync.WaitGroup
wg.Add(1)
for i := 0; i < 1000; i++ {
go systemCall()
}
go func() {
defer wg.Done()
http.ListenAndServe("localhost:4000", nil)
}()
wg.Wait()
}
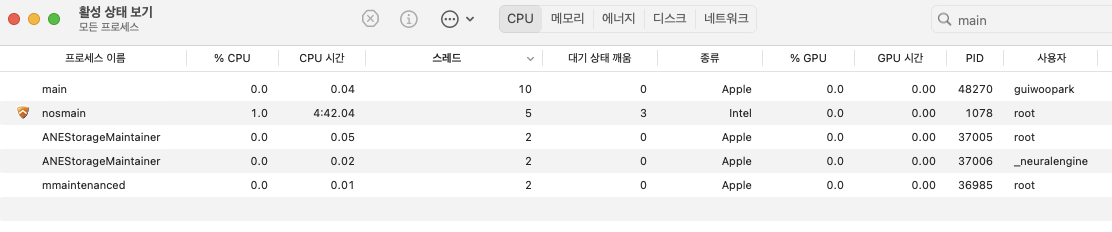
보이는 것처럼 1000번 을 시스템 호출을 하게 된다.
시스템호출로 파일을 열고, 읽는 작업을 수행하는데 기본생성 스레드 7개를 제외하면 총 4개의 스레드만 생성해서 1000번의 시스템 호출을 해결했다는 의미이다.
위에서 말한 GMP가 적용되어 스레드가 유휴상태가 되면 다른 고 루틴으로 변경해서 적용하는 모습을 확인할 수 있다.
만약 사용자와 인터페이스 하는 블로킹 작업이 계속된다고 가정하면 어떻게 될까?
func systemCall() {
fmt.Println("system call ")
buf := make([]byte, 1024)
syscall.Read(0, buf)
fmt.Println("system call done")
}
func main() {
var wg sync.WaitGroup
wg.Add(1)
for i := 0; i < 1000; i++ {
go systemCall()
}
go func() {
defer wg.Done()
http.ListenAndServe("localhost:4000", nil)
}()
wg.Wait()
}
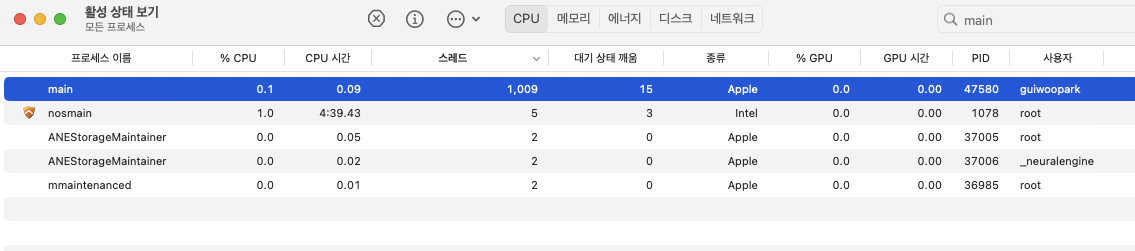
syscall.Read로 사용자의 인풋을 받아오는 시스템콜이다.
해당 시스템콜을 호출을 하게 되면 고 루틴 이 총 1005개, 생성된 스레드가 1009개이다.
위의 경우는 I/O작업으로 인해 생긴 블로킹이고 스레드가 유휴상태에 빠지게 된다 그에 따라 고 루틴 하나가 통으로 떨어져 나간다는 사실을 확인할 수 있다.
여기서 사용자가 인풋을 넣게 된다면?
고 루틴은 회수되고 스레드는 회수되지 않는다.
고 루틴이야 당연히 고루틴의 함수의 끝까지 도달해 고루틴이 가비지컬렉터에 의해 수거된다.
그러나 스레드의 경우 Go런타임이 즉각적으로 반환하지 않고 스레드 풀을 유지하기 때문에 블로킹이 해소되더라도 스레드의 반환이 즉시 일어나지 않을 수 있다.
재사용되는 스레드에 따라 컨택스트 스위칭이 덜 발생하게 되고 이는 속도적인 측면에 즉각적으로 연결된다.
고 루틴은 경량스레드이다. 직접적인 스레드가 아닌 고런타임에서 논리프로세스가 관리해주는 스레드이다.
고 루틴은 GMP모델을 이용해 커널 스레드를 효율적으로 사용할수 있다.
이 처럼 IO바운드 작업에 있어서 고루틴은 엄청난 효율을 자랑하고 있으니 고루틴 사용에 대해 생각해 보자.
참조
[1] https://20h.dev/post/golang/goroutine/
[2] https://d2.naver.com/helloworld/0814313
[3] https://ykarma1996.tistory.com/188
[4] https://www.ardanlabs.com/blog/2018/12/scheduling-in-go-part3.html
'Go > 고루틴' 카테고리의 다른 글
| SSE 알람 레이스 컨디션 해결 (0) | 2024.07.07 |
|---|---|
| SSE 알람 문제 해결과정 기록 (feat 고루틴) (0) | 2024.06.24 |
| 고루틴 메모리 누수 - 프로파일링 (0) | 2023.08.24 |
| [Concurrency in Go] 6장 고루틴과 Go 런타임 (0) | 2023.08.15 |
| [Concurrency in Go] 4장 Go의 동시성 패턴 -4 (0) | 2023.06.25 |