지난 한 개의 프로젝트 종료 이후 새로운 프로젝트의 담당이 되었다. 증권방송 관련된 개발 건이었는데, 생각보다 개발의 소요가 크지 않았다.
스페이스 리뷰커밋 기준으로 작성한다.
1. 스웨거 수정
이번 프로젝트는 지난프로젝트 와 달리 스웨거가 존재한다. API 문서 가 따로 존재하지 않고 이렇게 스웨거로 있다 보니 정말 편하다. 지난 프로젝트는 생각보다 읽어야 할 문서 가 많고 버전관리가 잘되지 않고 있어서 직접 코드를 확인해서 검증하는 2번씩 봐야 했다면, 스웨거가 있어 정말 비즈니스에 대해 빠르게 파악이 가능했다. 다만 몇몇 스웨거는 작동되지 않고 있어서 수정이 필요했는데.
예전 개인프로젝트 간에 작성했던 스웨거 와는 너무 달랐다. 어노테이션을 이용해 클래스 필드 위에 작성을 했었는데. 여기 적혀있는것은 swager.html , rapidoc.js, 그다음 호출에 대한 request, response의 json 데이터이다. 간략하게 보여주자면

요런 식으로 json 파일에 원하는 주소와 스키마 그리고 값을 입력해 주는 방식인데 생각보다 괜찮다. 당연히 이렇게 swagger.html을 서버와 같이 말아 올려 야하기 때문에 static에 넣어서 사용하는 게 생각보다 좋은 거 같다. 다만 저 json 파일에서 수정할 때 생각보다 헷갈린다.
2. 버전업 API
보통 신규 api 가 아닌 기존 api 를 수정할 때 이렇게 버전업 전략을 사용한다고 한다. 기존 api를 사용하던 곳에서 생길 문제를 이렇게 예방한다고 하는데 이런 부분에 있어 생각을 해보지 않아 api/개발/필요로 바로 개발했다가 위와 같은 설명을 듣고 v1.2 이런 식으로 추가해서 변경했다.
전체적인 로직이 변경되지 않는이상 대체적으로 파라미터를 하나 추가하는 편인데, 쿼리 자체가 변경되어야 한다고 판단해서 위와 같이 버전업을 선택했다.
- 테스트 코드
확실히 이번에는 시간적인 여유가 많이 있어 TDD 도 적용했다. 아무래도 기존 프로젝트 에 testify 같은 라이브러리의 접목이 과하다고 생각되어 그냥 일반적으로 interface로 모킹을 적용해 작성했다.
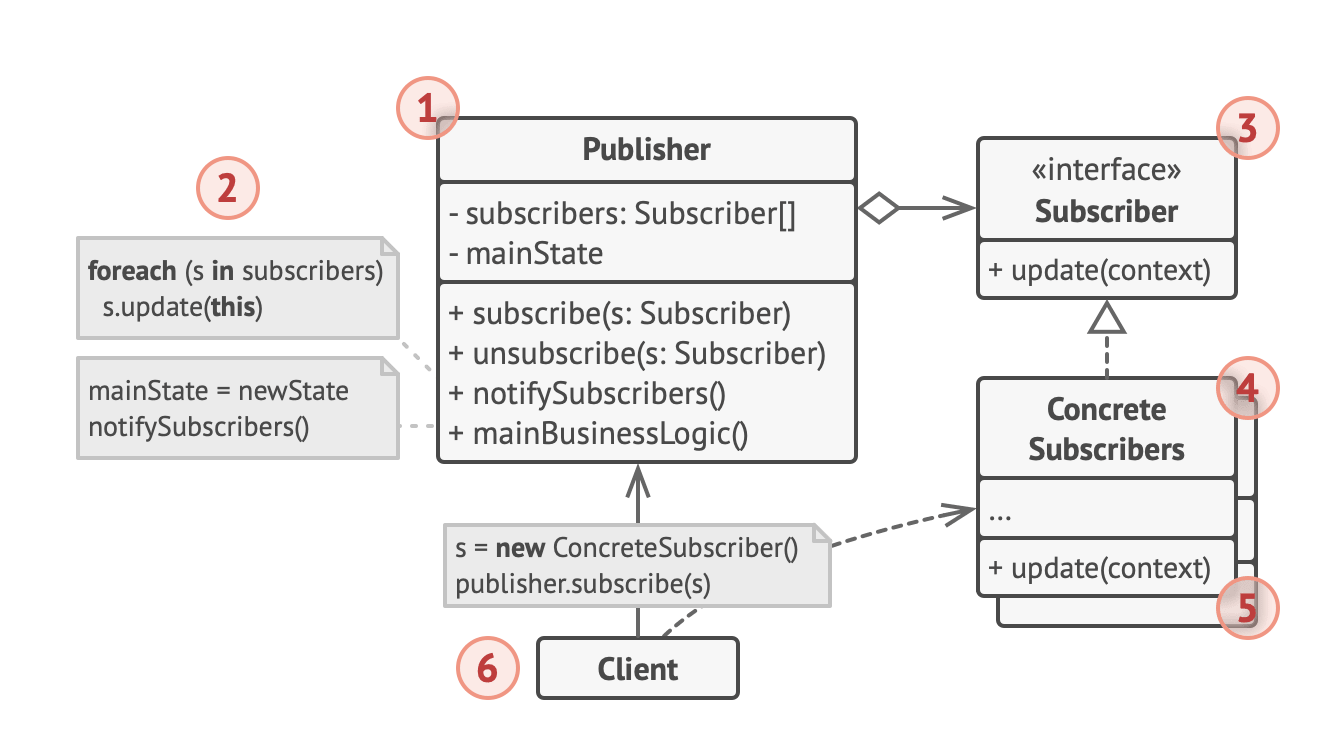
Go에서 지향하는 테이블 주도 테스트이다 아래와 같다.



위와 같은 방식으로 functionName 을 집어넣어 내가 테스트하고자 하는 함수에 대해 분기를 나눠주기 위해 iota를 적용해 작성했다. 자바로 치면 enum이라고 생각하면 편하겠다.
우측 사진에 보이는것처럼 테스트하고자 하는 서버스의 목 데이터를 넣어서 테스트해주면 된다.
고에서는 test 코드 안에서 서로 임포트가 불가능하다 따라서 이렇게 mock 폴더를 만들어서 관리를 해주었다.


LiveListInjectMock 은 인터페이스이다.
그래서 Success와 Fail 케이스는 각각 저 인터페이스를 구현하고
해당 서비스에서는 LiveListInject 인터페이스를 주입받아 호출을 하게 된다면? 성공 실패 원하는 주입을 통해 테스트를 효과적으로 할 수 있다.
그래서 첫 번째 위의 사진에 첨부된 코드 중 이렇게 주입이 가능해지는 것이다.
&mock.MockLiveService{LiveListInjectMock: mock.LiveListMockFail{}},
물론 이렇게 테스트 가 가능한 이유는 기존 구현된 모든 서비스 들은 추상화되어있기에 이런 식의 코드 구현이 가능하다.(이래서 코드 설계 디자인이 너무 중요한 것 같다.)
확실히 디자인패턴 의 공부가 이런 쪽에 있어서는 정말 도움이 많이 되는 것 같다.
3. 검색 API 파람 추가
기존 검색에 추가적인 파라미터가 필요했다. 예를 들어 1,2 로만 가능했던 검색이 이제는 3이라는 옵션도 추가되어야 했고 3은 전혀 다른 쿼리가 나가야 했다.
이에 따라 enum을 이용해 swith 문으로 해결했다.
swich case 3: 새로운 로직 default : 기존로직 이렇게 작성된다면 기존 코드 의 사이드 이펙트 없이 수정이 가능하나 기존함수를 수정해야 하기 때문에 쿼리에 대한테스트가 필수적이다.
-gorm prealod 기능
gorm 은 eagar 기능 인 프리로드를 지원해 준다. in query로 한방에 날려주는데 생각보다 성능이 좋다.
다만 이번 에는 preload를 서브쿼리를 적용해서 사용했어야 했는데 생각보다 코드가 깔끔하다.
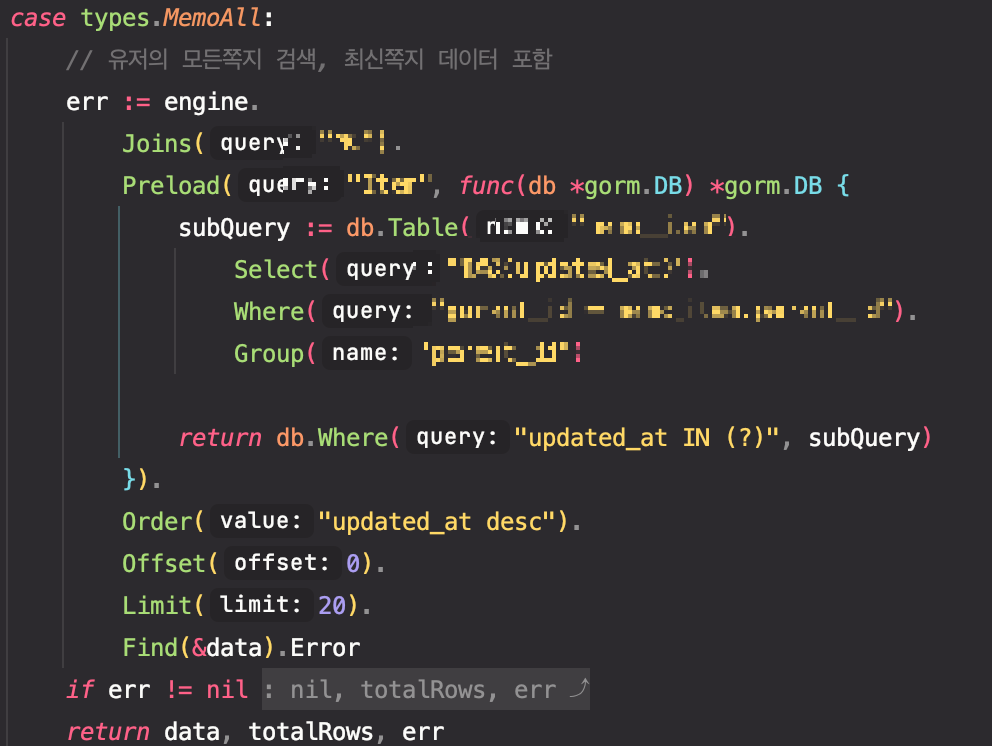
생각보다 코드가 명확해서 읽는 사람도 편하다 다만 서브쿼리의 경우 위에 보이는 것처럼 스트링으로 처리하기 때문에 오타가 나면 생각보다 찾기 어려우니 주의하자.
메인 쿼리는 index_merge, eq_ref
프리로드 쿼리 는 range, eq_ref, index
메인쿼리의 index_merge는 검색해 보니 생각보다 성능이 좋은 편은 아니라고 한다. 테이블에 설정된 여러 인덱스를 태워야 하기 때문이라는데 디비 설계상 중복된 데이터가 메인쿼리에서 발생할 수 없다고 판단했다. 테이블에 존재하는 인덱스 칼럼들은 연관관계없는 테이블에 대해 참조가 필요했기에 인덱스가 걸려있어, 중복데이터 발생이 없다고 판단하고 넘어갔다.
*추가적으로 개발건에 대해 기존코드 수정은 위와 같이 코멘트를 남기려고 노력한다. 비즈니스 가 변경되고 ,특정한이유에 있어 추가되는 코드들은 상식적으로 맞지않고, 처음보는 사람에게 읽기 어려운 코드를 제공한다고 생각한다. 비즈니스로직 의 히스토리를 모르고 있다면 코드독해에 상당한 어려움이 있고 실제로 지난 프로젝트에서 상당한 어려움을 겪어 위와같이 커멘트를 작성하고자 한다.
-테스트 코드
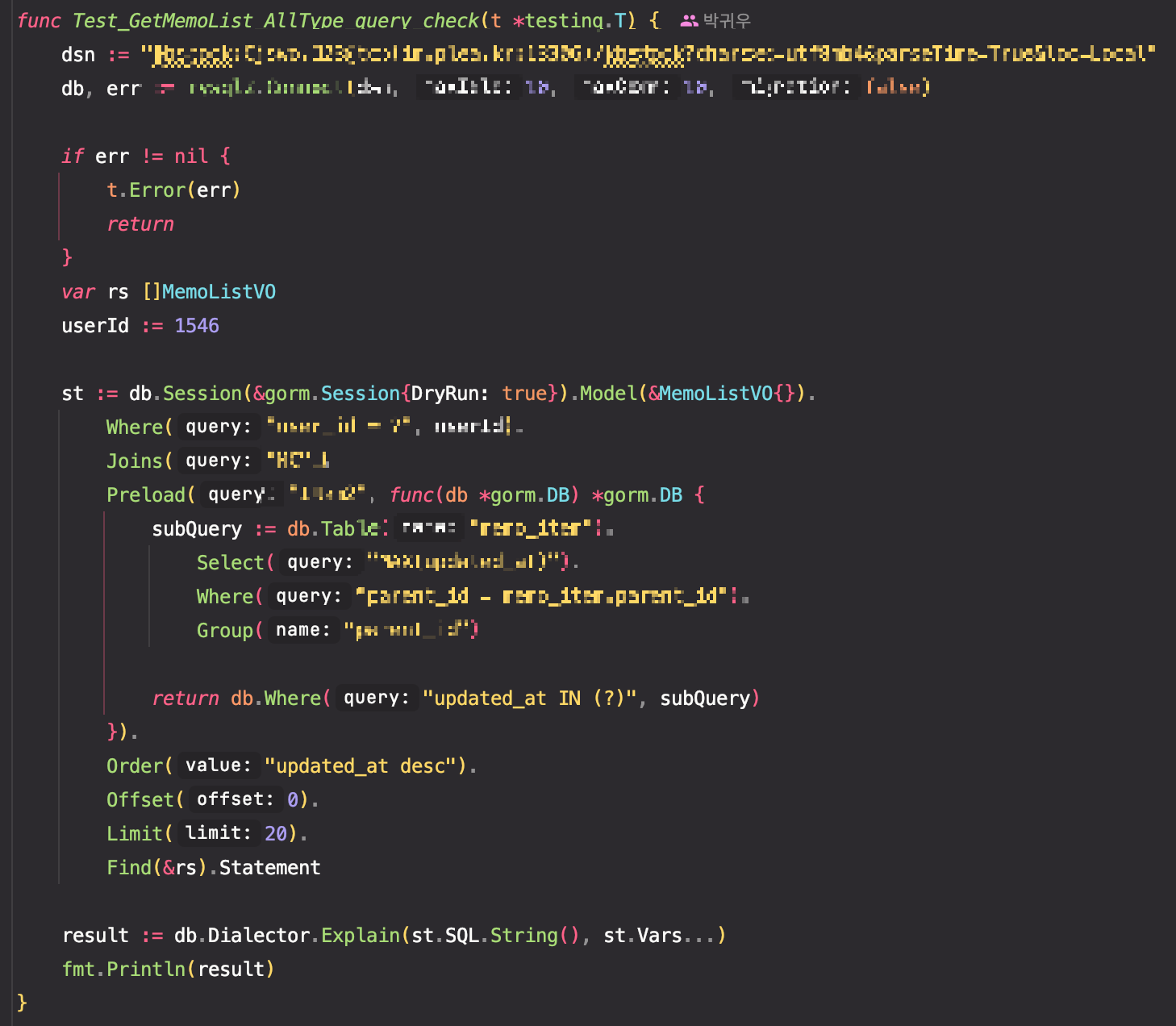
테스트 코드는 단순 쿼리 확인을 위해 dryrun 옵션을 세션에 추가해 작성했다.
dryrun 은 실행되는 쿼리의 쿼리 스트링만을 뽑아낼 수 있어며 아래 보이는 result처럼 어떤 쿼리가 발생되는지에 대해 쿼리로 뽑아서 확인할 수 있다.
다만 문제점으로는 preload로 실행되는 서브쿼리와 인쿼리는 제공되지 않아 추가적인 쿼리 확인은 다른 테스트 방식이 요구된다.
따라서 메인쿼리의 확인을 위해 위와 같이 작성했고, 프리로드 쿼리의 확인을 위해 직접적인 디비호출을 실행했다.
4. CORS 에러
문제점 : 우리는 ovp 플랫폼을 사용한다. ovp 플랫폼에서 제공되는 url을 토큰과 같이 프런트로 내려주게 되고 프런트는 이 url 경로를 통해 리소스를 요청한다. 문제는 url 경로를 통해서 요청되는 것은 redirect 요청이고 그 플랫폼에서는 redirect 요청에 따른 진짜 리소스를 제공하게 된다.
여기서 리다이렉트 하는 구간에서 CORS 에러가 발생하게 된다.
ovp 플랫폼에서 제공하는 플레이어를 이용한다면 cors 에러는 발생하지 않는다. 왜냐하면, hls로 요청하고(http live streaming protocall) 그걸 임베디드로 띄워서 사용하면 되기 때문에 문제가 없다.
그러나 pip 모드 문제점이 있어 videojs 라이브러리를 프런트 팀에서 선택하게 되고, 프런트에서 요청하고, 데이터를 받아와야 하는 상황에 처한 것이다.
소통의 중요함을 너무 크게 느꼈고, 에러의 문제점이 어디에서 도출되는지 에 대한 명확한 고민 없이 코드 확인부터 하다 보니 너무 많은 시간을 이 에러 핸들링에 소모했다.
1. cors 에러가 발생된다고 해서, 어떤 요청 어디에서 발생했는지에 대한 자료요청을 하지 않고, 서버의 cors 설정을 확인한 점
2. ovp 플랫폼과 연락해보지 않은 점
3. cors 발생의 헤더 나 리스폰스 값을 정확하게 한인 해보지 못한 점
4. 프런트와 의 소통미스 hls, m3u8 등 정확한 의미를 인지하지 못한 점
1,2,3,4번의 혼합으로 정말 크게 뺑 ~~~~ 돌아갔다.
결국 해당 ovp플랫폼에서는 우리와 같이 사용하는 케이스에 대해 인지하지 못했으며, 확인해 보겠다고 했으며 우리는 서버에서 요청해서 리다이렉트 URL을 파람에 추가해서 내려주기로 했다.
당장 7월 6일까지 테스트 서버 오픈이기에 위와 같은 방법으로 임시 해결책을 적용하였다. 이러한 방법이 해결책이기에 명확한 해결방법이 제공되었으면 좋겠다... 아니면 무엇을 놓쳤는지 정말 모르겠다.
5. SPA Static으로 말아 올리기
CORS와 같이 나를 오래 괴롭힌 문제였다. 문제의 요지는 아래와 같다.
spa이다 보니 routing 이 당연히 server에 열린 routing 과는 다르게 존재한다.
static 폴더와 경로의 마찰이 생길 것을 생각해, 새로운 프리픽스를 적용해서 관리하고 싶었다.
우리는 echo 프레임 워크를 사용한다. echo에서 제공해 주는 미들웨어 하나를 적용해서 작성했다.

정말 단순하다. 이렇게만 작성해 주면 된다. staticConfig 구조체의 설명 중 HTML5의 핵심설명만 보자면
// Enable HTML5 mode by forwarding all not-found requests to root so that
// SPA (single-page application) can handle the routing.
// Optional. Default value false.
오우 이렇게 지원을 다해주고 있다. 미친것 같다.
Root 같은 경우는 시작점에 대한 패스이다 이런 거는 config 파일을 통해 관리되고 있어 위와 같이 처리했다.
이렇게 말아 올렸는데 이게 무슨 일인가... 시작페이지에서 차례대로 들어간다면 정말 잘 들어가진다. 그러나 새로고침, 특정 주소입력에 대해 계속 메인 페이지로 돌아가는 게 아닌가...
해결해 보고자 e.Static으로 file 자체를 라우팅에 리턴해보기도 하고 여러 가지 삽질이란 삽질을 하루 온종일 했다.
결국 팀장님 께도움을 요청했고 1분 만에 찾아내셨다 ㅎ
요청되는 js 파일은 정상적으로 된다. 이건 백엔드 문제가 아니다.라고 하셨고 몇 번 더 확인해 보니. 토큰의 인증값이 사라져서 메인페이지로 리다이렉트 되는 게 아닌가? ㅎㅎ.......
CORS 도 그렇고 이것도 그렇고 개발자 도구를 좀 더 면밀하게 살펴보았다면 문제 해결에 있어 상당한 시간이 줄어들었다고 판단된다.
6. script 작성
매번 프런트의 푸시 이후 배포를 수정해 주어하는 불편함이 있었다. 테스트 서버에 대해 ci/cd 가 설정되어 있지 않아 매번 linux로 파일을 밀어 넣어야 했는데, 매번 배포 후 부탁하시는 모습이 불편해 보여 스크립트 하나작성해서 보내드렸더니 너무 좋아하신다.
스크립트 라고 해봐야 vue 빌드하고 scp로 서버에 날리고, 빌드된 폴더를 삭제하는 꼴랑 몇 줄 안 되는데..
#!/bin/sh
echo 빌드 폴더 사내서버 패치
echo 빌드 Vue 폴더
npm run build
sleep 1
scp "리눅스 주소 ㅎㅎ"
sleep 1
echo Dist 빌드폴더 삭제
rm -rf dist
echo 빌드 폴더 사내서버 패치 완료bash 스크립트 작성자에게 정말 초보처럼 보이고 이상해보일진 모르지만 누군가에게 도움이 되는 코드를 작성해서 생각보다 기분이 좋았다.
총평: 이번 프로젝트에서는 코드의 개발보다 프런트와 의 의사소통, 데이터 세팅 테스트 서버 구성 등 다양한 경험을 해볼 수 있는 시간이 되었던 것 같다. 나의 부족한 부분 특히 디버깅의 미숙한 부분이 생각보다 많이 느껴져서 부끄러웠으며, 테스트 코드 작성은 생각보다 즐거운 시간을 보낸 것 같다. 항상 이런 여유로운 시간에 따라 프로젝트를 하고 싶지만 이건 꿈같은 바람이지 않을까 한다. 테스트 코드 통과를 마지막으로 글을 마치고자 한다.