지난번 포스팅을 통해 서비스에서 올바르게 작동하는 SSE가 구현되어 POC(개발의 기능구현이 클라이언트의 의도대로 되는지 확인하는 시험)도 잘 마무리되었지만. 마음의 짐이 남아있었다.
지난번 구현과정 에서 레이스컨디션을 발견했다. (https://guiwoo.tistory.com/96)
프로파일링 검증이 마무리되고 레이스컨디션으로 다시 실행하던 도중 발견하게 되었다.


해당 레이스 컨디션의 문제의 구간은
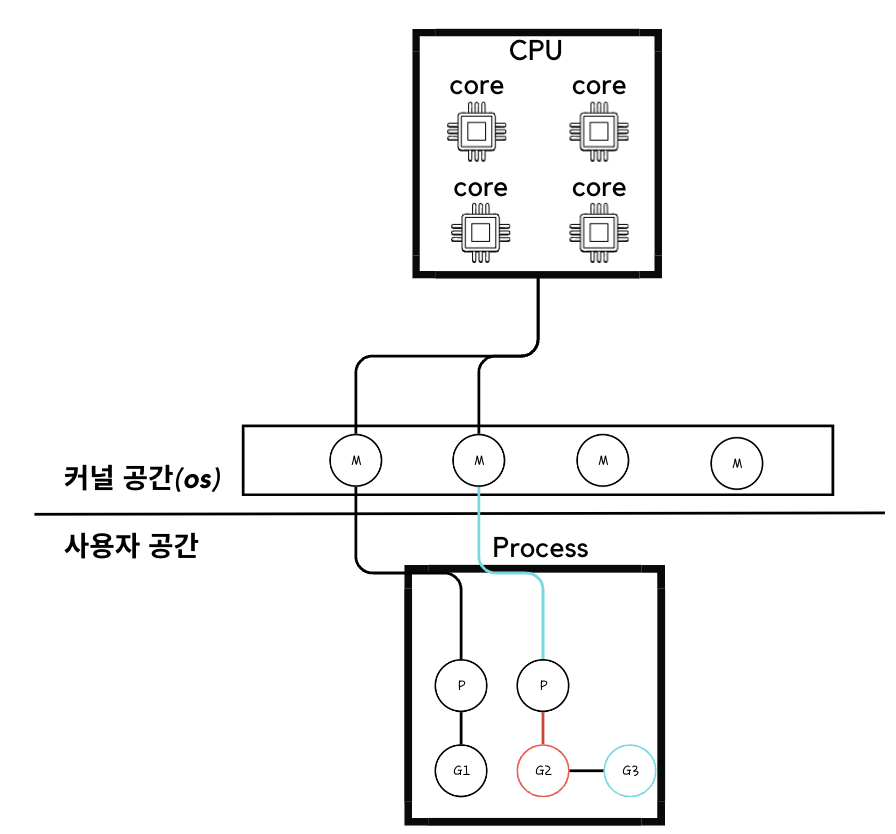
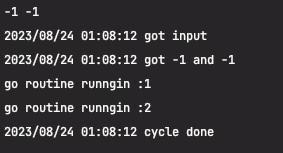
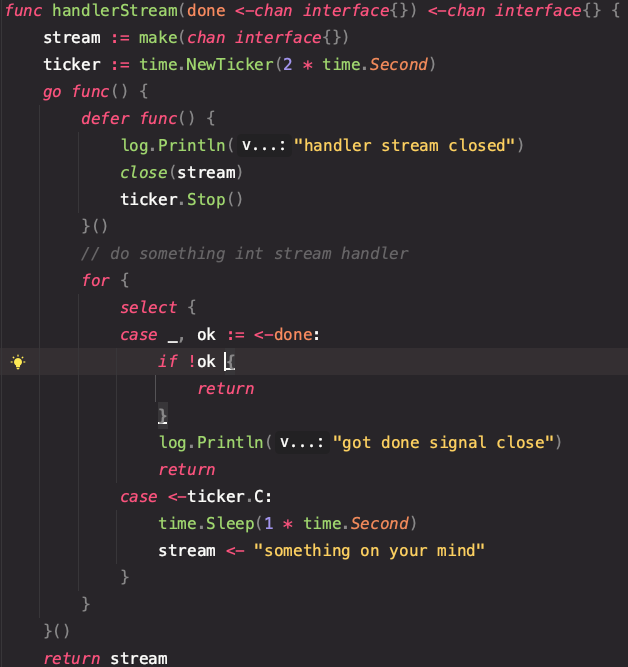
허브 클라이언트를 통해 개별적으로 관리되는 map 데이터 상에서 알람의 메시지를 지우고 생성하는 과정에서 유저의 연속적인 등록, 해제가 발생될 시 레이스 컨디션이 발생하게 된다.

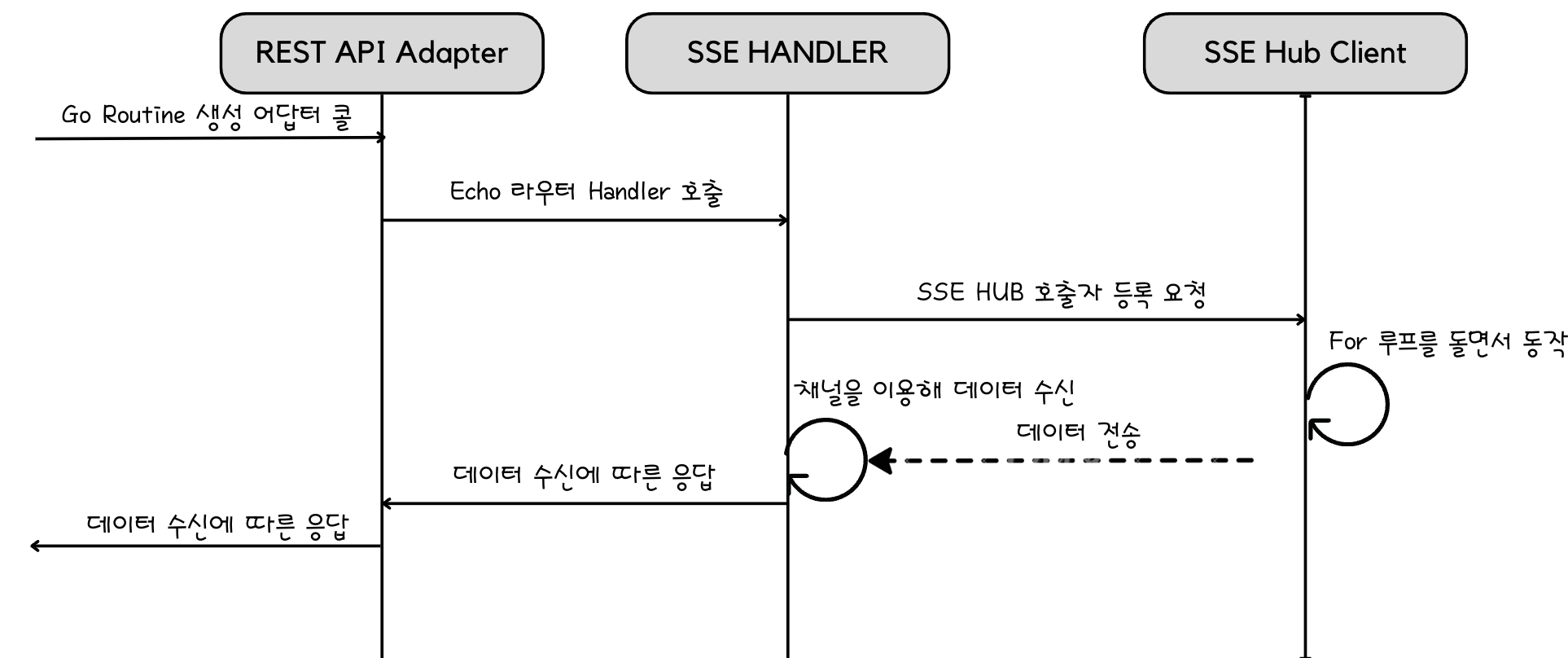
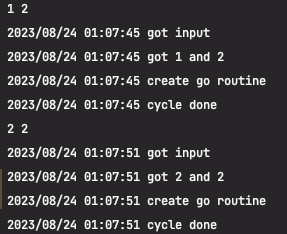
지난번 작성한 요청의 따른 예시이다.
1. Request 콜 요청에 따른 고루틴 생성으로 핸들러의 함수를 호출하게 되고 핸들러는 다시 허브 클라이언트를 호출하여 데이터의 싱크를 맞추게 된다.
이에 따라 서버의 바이너리 파일이 실행되면
1. 서버가 실행되며,
2. Hub클라이언트가 배치의 성향을 가지고 데이터를 주기적으로 가져와 싱크를 맞추게 된다.
이렇게 됨에 따라 request요청은 고 루틴을 통해 핸들링이 될텐데, 허브에서 내부적으로 각 고 루틴의 요청을 처리함에 있어 문제가 발생되었던 것이다.
구조의 전체적인 점검을 위해 단계별로 다시 밟아가보자.
1. 단순한 구현 방법
각 request의 고루틴 요청에 할당하는 것 전체적인 구조가 쉽고 데이터와 고루틴의 관리포인트가 명확하다.

코드를 확인해 보자.
// 핸들러 내부 구현
sse.GET("/call/:id", func(c echo.Context) error {
time.Sleep(500 * time.Millisecond)
id := c.Param("id")
done := make(chan bool)
log.Info().Msgf("Get Request Id :%+v", id)
log.Info().Msgf("after register")
go func(done chan bool, id string) {
ticker := time.NewTicker(500 * time.Millisecond)
defer log.Info().Msgf("go routine return")
for {
select {
case <-ticker.C:
c.Response().Header().Set("Content-Type", "text/event-stream")
c.Response().Header().Set("Cache-Control", "no-cache")
c.Response().Header().Set("Connection", "keep-alive")
str := fmt.Sprintf(`{"alarm":%v}`, getData(id))
if _, err := fmt.Fprintf(c.Response().Writer, "data: %s\n\n", str); err != nil {
log.Err(err).Msg("failed to send data")
}
c.Response().Flush()
case <-c.Request().Context().Done():
log.Info().Msg("get done signal from request")
done <- true
return
}
}
}(done, id)
<-done
log.Info().Msgf("pass the groutine")
log.Debug().Msgf("sse conection has been closed")
return nil
})
생각보다 간단하게 구현되어 있다. 가장 기본이 되는 done 채널의 종료 시그널을 밖으로부터 받아와 <- done 라인의 블락을 걸어 sync.WaitGroup 없이 처리했다.
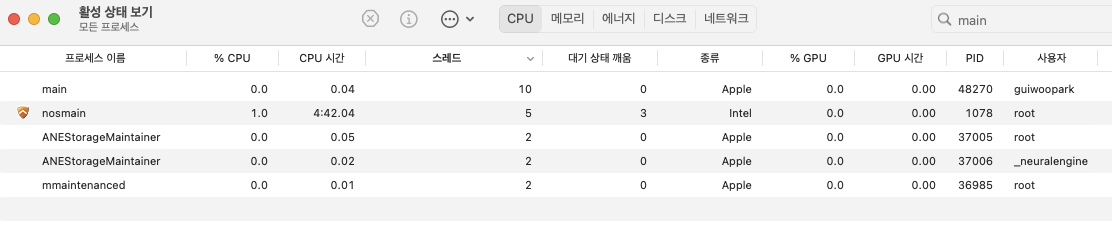
자 이렇게 되었을 때 프로파일링 및 레이스 컨디션을 확인했을 때 고 루틴의 누수와, 레이스컨디션이 존재해서는 안된다.



예상했던 결과이다.
위와 같이 구성된 경우 각 request는 각자의 고유한 메모리를 할당해서 사용하기 때문에 레이스컨디션은 존재하지 않는다.
만약 700명의 사용자가 이용한다면? 700개의 고 루틴이 생성되고, DB의 요청은 매 0.5초마다 700건의 조회 요청이 날아가 병목지점이 발생하게 된다.
구조를 다시 개선해 보자.
하나의 공유메모리를 두어 DB결과를 저장하고 각 Request 핸들러 고 루틴에서는 해당 공유메모리의 결과를 가져오는 방법으로 개선을 한다면?
공유 메모리의 관리를 위한 관리 클라이언트와 DB 조회를 주기적으로 담당해 줄 클라이언트가 필요하다.

지난번 허브 클라이언트보다 생각보다 간단한 로직이다.
단순하게 배치성의 작업을 가지고 매 0.5초 단위로 알람이 있는 유저에 대해 조회해 와 공유 메모리에 저장하는 방식이다.
핸들러 코드는 그렇다면 아래와 같이 변경된다.
done := make(chan bool)
sse := e.Group("/sse")
sse.GET("/call/:id", func(c echo.Context) error {
id := c.Param("id")
log.Info().Msgf("Get Request Id :%+v", id)
log.Info().Msgf("after register")
go func(done chan bool, id string) {
ticker := time.NewTicker(500 * time.Millisecond)
defer log.Info().Msgf("go routine done")
for {
select {
case <-ticker.C:
c.Response().Header().Set("Content-Type", "text/event-stream")
c.Response().Header().Set("Cache-Control", "no-cache")
c.Response().Header().Set("Connection", "keep-alive")
str := fmt.Sprintf(`{"alarm":%v}`, hub.getAlarm(id))
if _, err := fmt.Fprintf(c.Response().Writer, "data: %s\n\n", str); err != nil {
log.Err(err).Msg("failed to send data")
}
c.Response().Flush()
case <-c.Request().Context().Done():
log.Info().Msg("get done signal from request")
done <- true
return
}
}
}(done, id)
<-done
log.Info().Msgf("pass the groutine")
log.Debug().Msgf("sse conection has been closed")
log.Debug().Msgf("sse conection has been closed")
return nil
})
허브클라이언트를 주입받아 단순하게 얻고자 하는 id를 얻는 방식이다.
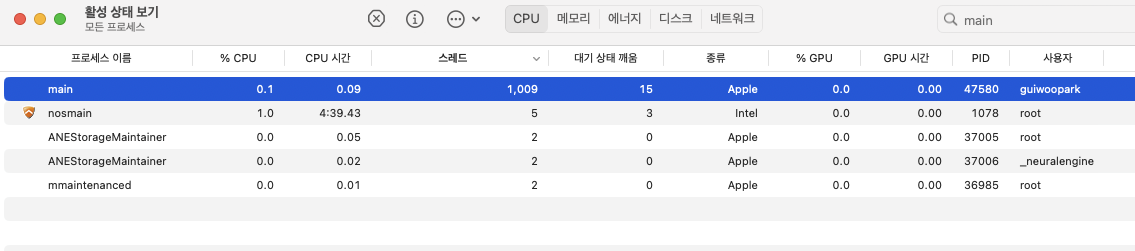
레이스 컨디션과, 고 루틴의 누수는 없어야 한다.



예상했던 대로 동작하고 있다.
조금 더 DB 최적화를 진행해 보자.
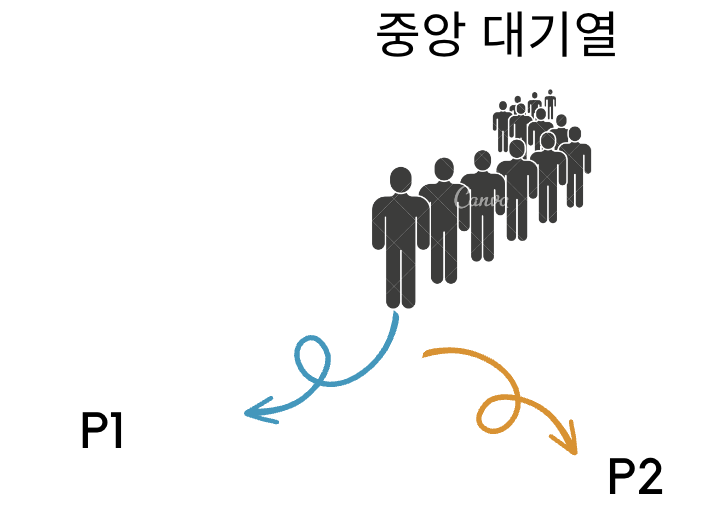
현재 두 번째 스텝에서는 모든 유저의 알람을 조회하는 방식이다. 이를 최적화하기 위해서는 접속한 유저의 알람만 조회하는 방법이다.

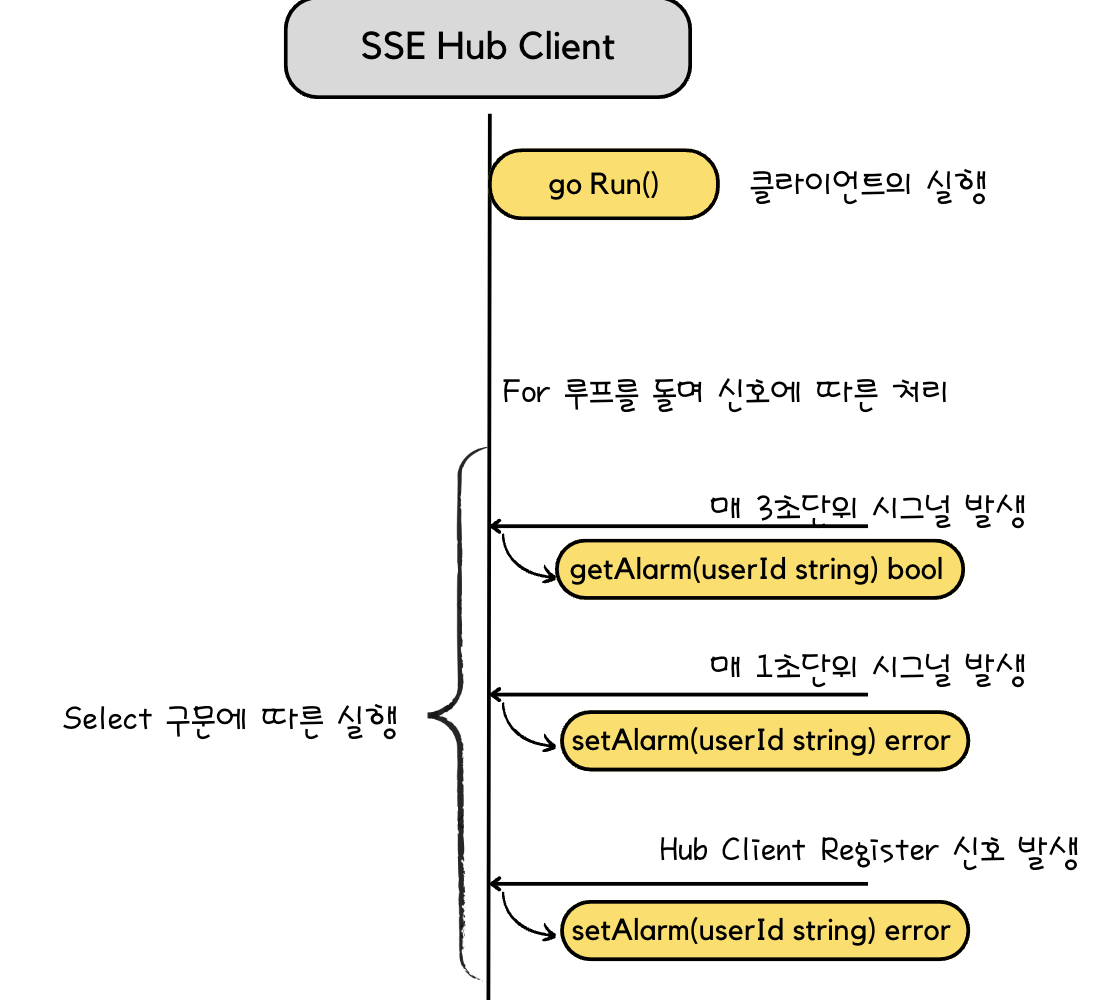
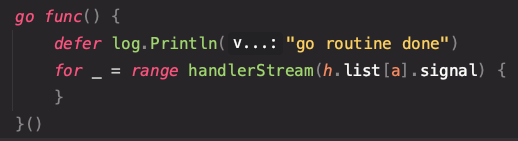
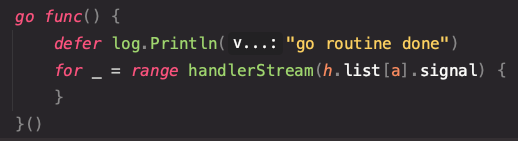
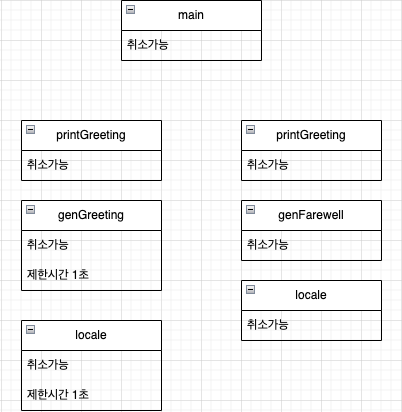
좌측이 이번에 구현하면서 변경된 포인트, 우측이 지난번에 구현한 select 구문이다.
차이점이라면 알람의 설정과 획득을 티커에 의해서 실행되는 것이 아닌 HubClient 호출부에서 해결하고 있다는 점이다.
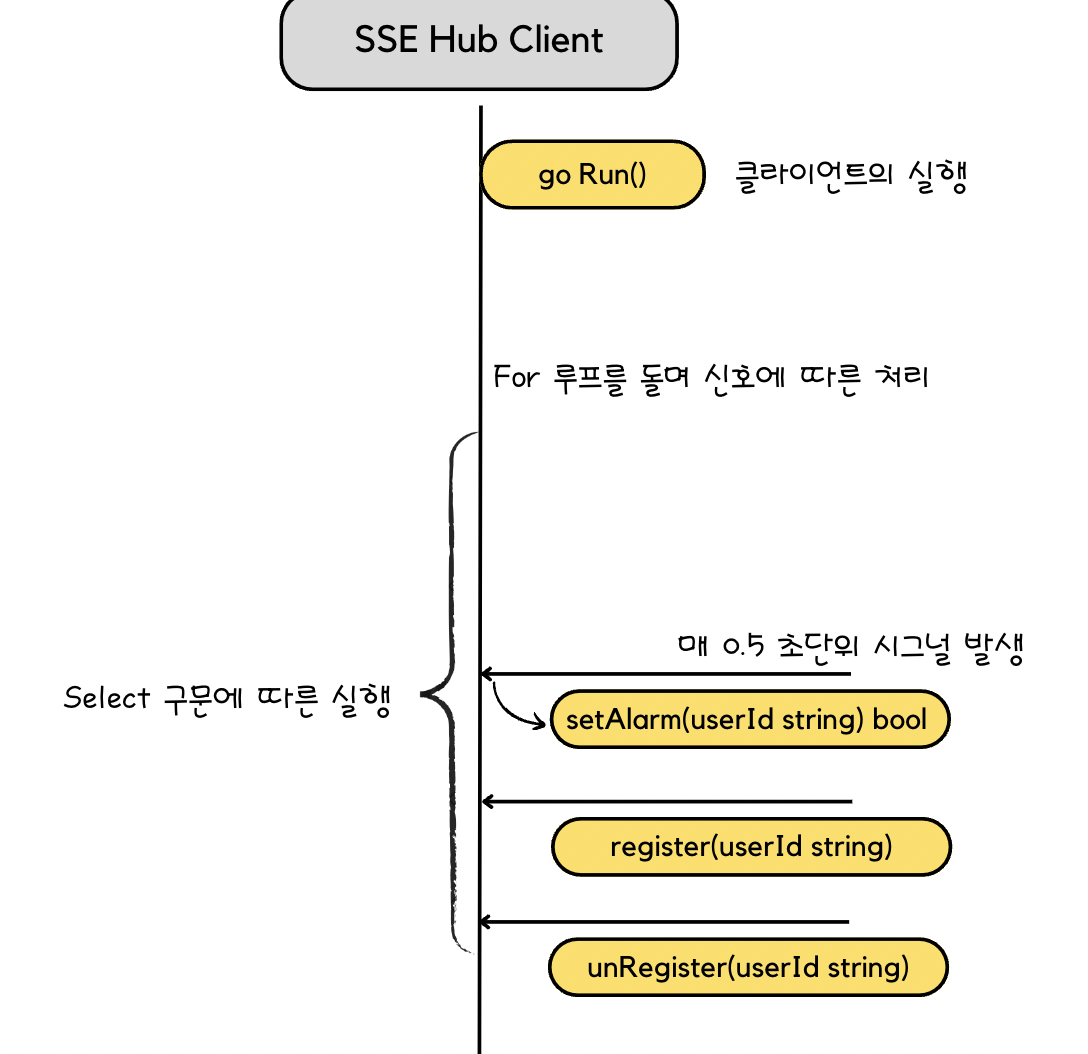
허브 클라이언트의 Run 함수는 아래와 같이 변경되었으며 지난번 구현보다 코드의 양이 훨씬 줄었다.
func (client *HubClient) Run() {
defer func() {
if err := recover(); err != nil {
client.log.Err(fmt.Errorf("panic and recover here")).Msgf("panic and recover %+v", err)
}
}()
var (
getDbTicker = time.NewTicker(500 * time.Millisecond)
)
for {
select {
case <-getDbTicker.C:
client.setAlarm()
case id := <-client.register:
client.setUserAlarm(id)
case id := <-client.unregister:
client.unRegister(id)
}
}
}
func (client *HubClient) GetAlarm(id string) bool {
// 알람을 가져온다.
}
func (client *HubClient) Connect(id string) {
// register 신호를 보낸다.
}
func (client *HubClient) Disconnect(id string) {
// unregister 신호를 보낸다.
}
func (client *HubClient) setUserAlarm(id string) {
// 등록된 유저의 정보를 저장한다.
}
func (client *HubClient) unRegister(id string) {
// 유저의 정보를 삭제한다.
}
코드의 가독성과 문제의 지점에 대해 확인하기 쉬워졌고, 지난번 보다 안정적인 sse 클라이언트 구현이 되었다고 생각한다.
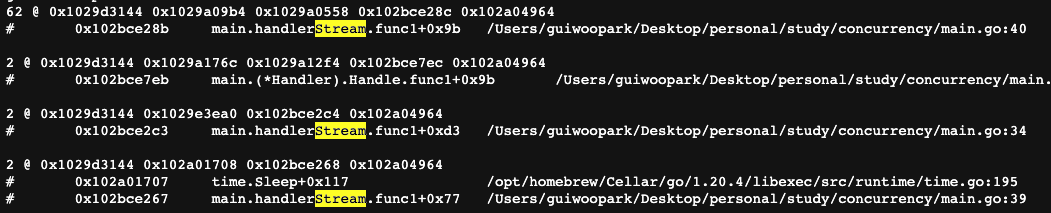
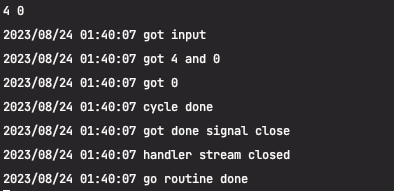
아래 레이스 컨디션 플래그 실행과, 프로파일링 결과가 말해주고 있다.


이렇게 단계 별로 확인을 해보면 간단하게 구현될 부분이었는데 고 루틴과 채널의 잘못된 사용으로 레이스컨디션, 고루틴 누수등의 문제를 겪었다.
동시성을 해결하기 위해 채널링을 사용하고, 병렬성의 문제를 해결하기 위해서는 mutex를 활용해서 메모리를 관리를 했어야 했는데
이러한 채널과 mutex활용에 있어 미숙한 점으로 인하여 지난번과 같은 문제가 발생했다.
다음에는 이러한 단계별로 구현을 직접 구현을 하지는 않더라도
어떠한 문제가 있고 그 문제를 해결하기 위해 어떠한 방법을 적용했는가? 에 대해 보다 명확하게 정리를 하면서 구현을 해야겠다.
코드 전문 (https://github.com/Guiwoo/go_study/tree/master/sse)
최종구현 클라이언트
package third
import (
"fmt"
"github.com/rs/zerolog"
"sync"
"time"
)
var arr []string
func init() {
n := int('z'-'a') + 1
arr = make([]string, 0, n)
for i := 0; i < n; i++ {
arr = append(arr, string('a'+i))
}
fmt.Println(arr)
}
type HubClient struct {
log zerolog.Logger
alarms map[string]bool
mutex sync.Mutex
register chan string
unregister chan string
}
func (client *HubClient) setAlarm() {
time.Sleep(500 * time.Millisecond)
client.mutex.Lock()
for _, id := range arr {
x := time.Now().Unix()
if x%2 == 0 {
client.alarms[id] = true
} else {
client.alarms[id] = false
}
}
client.mutex.Unlock()
}
func (client *HubClient) GetAlarm(id string) bool {
a := false
client.mutex.Lock()
a = client.alarms[id]
client.mutex.Unlock()
return a
}
func (client *HubClient) Connect(id string) {
client.register <- id
}
func (client *HubClient) Disconnect(id string) {
client.unregister <- id
}
func (client *HubClient) setUserAlarm(id string) {
client.mutex.Lock()
client.alarms[id] = false
client.mutex.Unlock()
}
func (client *HubClient) unRegister(id string) {
client.mutex.Lock()
delete(client.alarms, id)
client.mutex.Unlock()
}
func (client *HubClient) Run() {
defer func() {
if err := recover(); err != nil {
client.log.Err(fmt.Errorf("panic and recover here")).Msgf("panic and recover %+v", err)
}
}()
var (
getDbTicker = time.NewTicker(500 * time.Millisecond)
)
for {
select {
case <-getDbTicker.C:
client.setAlarm()
case id := <-client.register:
client.setUserAlarm(id)
case id := <-client.unregister:
client.unRegister(id)
}
}
}
func NewHubClient(log *zerolog.Logger) *HubClient {
return &HubClient{
log: log.With().Str("component", "HUB CLIENT").Logger(),
alarms: make(map[string]bool),
mutex: sync.Mutex{},
register: make(chan string),
unregister: make(chan string),
}
}main 함수
package main
import (
"fmt"
"github.com/labstack/echo/v4"
"github.com/labstack/echo/v4/middleware"
"github.com/rs/zerolog"
"net/http"
_ "net/http/pprof"
"os"
"sse/client/third"
"time"
)
func main() {
e := echo.New()
log := zerolog.New(zerolog.ConsoleWriter{Out: os.Stdout}).With().Timestamp().Logger()
hub := third.NewHubClient(&log)
go hub.Run()
e.Use(
middleware.Recover(),
middleware.LoggerWithConfig(middleware.LoggerConfig{}),
)
done := make(chan bool)
sse := e.Group("/sse")
sse.GET("/call/:id", func(c echo.Context) error {
id := c.Param("id")
log.Info().Msgf("Get Request Id :%+v", id)
hub.Connect(id)
log.Info().Msgf("after register")
go func(done chan bool, id string) {
ticker := time.NewTicker(500 * time.Millisecond)
defer log.Info().Msgf("go routine done")
for {
select {
case <-ticker.C:
c.Response().Header().Set("Content-Type", "text/event-stream")
c.Response().Header().Set("Cache-Control", "no-cache")
c.Response().Header().Set("Connection", "keep-alive")
str := fmt.Sprintf(`{"alarm":%v}`, hub.GetAlarm(id))
if _, err := fmt.Fprintf(c.Response().Writer, "data: %s\n\n", str); err != nil {
log.Err(err).Msg("failed to send data")
}
c.Response().Flush()
case <-c.Request().Context().Done():
log.Info().Msg("get done signal from request")
hub.Disconnect(id)
done <- true
return
}
}
}(done, id)
<-done
log.Info().Msgf("pass the groutine")
log.Debug().Msgf("sse conection has been closed")
log.Debug().Msgf("sse conection has been closed")
return nil
})
go func() {
http.ListenAndServe("0.0.0.0:6060", nil)
}()
if err := e.Start(":8080"); err != nil {
log.Err(err).Msg("fail to start server")
}
}'Go > 고루틴' 카테고리의 다른 글
| SSE 알람 문제 해결과정 기록 (feat 고루틴) (0) | 2024.06.24 |
|---|---|
| 고루틴은 어떻게 동작하는가 (1) | 2023.11.16 |
| 고루틴 메모리 누수 - 프로파일링 (0) | 2023.08.24 |
| [Concurrency in Go] 6장 고루틴과 Go 런타임 (0) | 2023.08.15 |
| [Concurrency in Go] 4장 Go의 동시성 패턴 -4 (0) | 2023.06.25 |