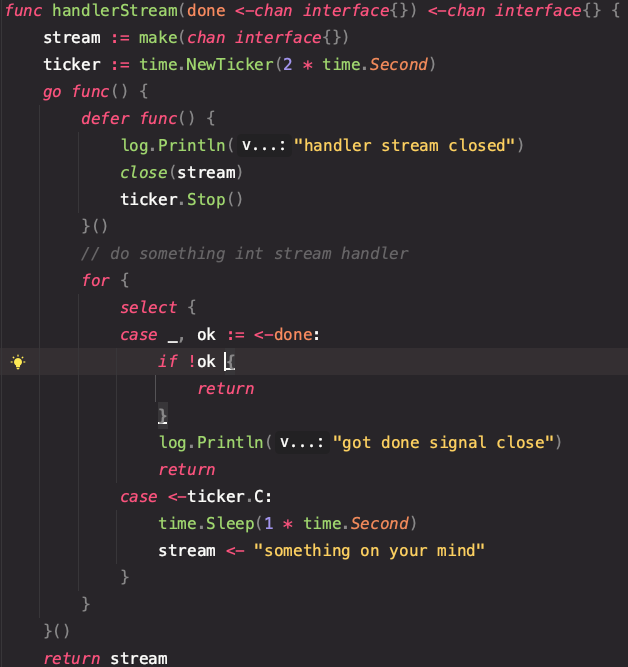
엄청 오랜만에 작성하는 글이다.
프로젝트에서 중간중간 긴급하게 수정하고, 내가 부족한 부분이 많아 상당한 부분을 리팩터링 하는데 시간을 보내 개인적인 공부할 시간조차 할애하기 어려웠다. 변명은 그만하고 바로 가보자.
이번 챕터는 데이터 구조이다. 바로 가보자.
배열 Array
1-1. CPU 캐시
코어들은 메인 메모리에 바로 접근하지 않고, 로컬 캐시로 접근한다. 캐시의 속도는 L1, L2, L3 메모리 순으로 빠르고 "퍼포먼스"가 중요하다면 모두 캐시메모리에 접근해야 한다.
1-2. Cache miss
캐시 미스란 코어에서 처리하고자 하는 데이터가 캐시에 없는 상태를 말한다. 위의 CPU캐시에 없다면 메인 메모리까지 접근해야 하고 이는 성능상 캐시보다 많이 느린 성능을 제공하게 된다.
프로세스는 프래패쳐를 가지고 있는데 이는 어떤 데이터가 필요할지 예상하는 것을 말한다. 다시 말해 프리패쳐를 이용해 예측가능한 데이터 접근 패턴을 생성하는 코드를 작성하는 것 이것이 캐시미스를 줄이는 방법이다.
그래서 이 캐시 미스, CPU 캐시랑 Array와 도대체 무슨 관련이 있는가?라고 생각이 들 수 있다. 배열은 메모리의 연속할 등을 하게 된다. 다
시말해 배열로 할당하고 이를 순회한다면? 이는 캐시미스의 확률을 상당히 줄여주게 된다.
n*n의 큰 행렬이 있다고 할 때 이를 순회하기 위해
1. LinkedList 순회 : TLB 변환색인버퍼 페이지와 오프셋을 이용해 중간 성능을 가지게 된다.
2. 열 순회 : 열순회는 캐시 라인을 순회하지 않는다. 메모리 임의접근패턴을 가진다.
3. 행 순회 : 행순회는 캐시 라인을 순회하며 예측 가능한 접근패턴을 만든다.
성능의 우선순위를 구분하면? 3 > 1 > 2의 순서를 가진다.
1-3. TLB 변환 색인버퍼
캐싱 시스템은 하드웨어로 한 번에 64바이트(기계별로 다르다) 씩 데이터를 옮긴다. 운영 체제는 4k 바이트씩 페이징 함으로써 메모리를 관리한다.
관리되는 모든 페이지는 가상 메모리주소를 갖게 되는데, 올바른 페이지에 매핑되고 물리적 메모리로 오프셋 하기 위해 사용된다.
여기서 위에서 linkedList 가 중간 성능을 가지는 이유를 알 수 있다.
다수의 노드가 같은 페이지에 있기 때문이다.
그렇다면 왜 열순위가 마지막 순위에 도달하는가? 일반적으로 캐시미스, 변환색인버퍼 미스가 둘 다 발생할 수 있는 게 열 순회의 경우이다.
위의 1,2,3 모두 지향하는 바는 똑같다. 데이터 지향설계
효율적인 알고리즘에 그치지 않고, 어떻게 데이터에 접근하는 것이 알고리즘 보다 성능에 좋은 영향을 미칠지 고려하는 것
배열을 왜 써야 하는지 배열을 쓰면 어떻게 동작하는지에 대해 알아보았다. 실질적으로 코드에서 어떻게 작성하고 선언하는지에 대해 알아보자.
var string [5]string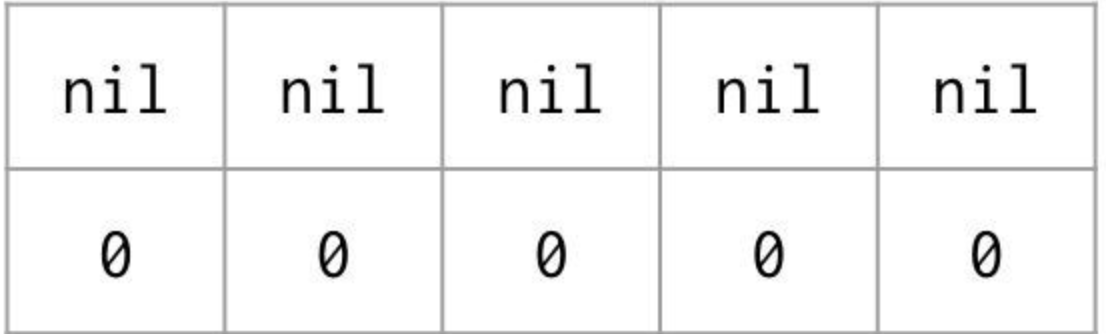
위와 같이 선언하게 되면 각 배열은 위의 그림과 같은 형태의 제로값으로 설정된다. 문자열은? 포인터와 길이를 표현하는 2 단어로 표현되기 때문이다.
fmt.Printf("\n=> Iterate over array\n")
for i, fruit := range strings {
fmt.Println(i, fruit)
}해당 코드블록과 같이
Println을 호출할 때 같은 배열을 공유하는 4개의 문자열을 가지게 되는 것이다. 문자열의 주소를 함수에 전달하지 않으면 이점이 있다. 문자열의 길이를 알고 있으니 스택에 둘 수 있고, 그 덕분에 힙에 할당하여 GC를 해야 하는 부담을 덜게 된다. 문자열은 값을 전달하여 스택에 둘 수 있게 디자인되어
이런 설명이 붙는데 한참 다시 읽어 봤다.
fruit는 string의 값을 하나씩 복사해서 선언된 메모리 주소에 계속 덮어 씌운다. Println 은 Go의 함수와 같이 파라미터로 전달된 값은? value 복사를 하게 된다. 그렇기 때문에 매번 함수가 호출될 때마다 매번 다른 fruit의 값을 프린트할 수 있게 되는 것이고,
힙에서는 공유되는 fruit에 대해서만 가비지컬렉팅이 발생되고, 프린트 함수에서는? 복사된 값을 가지기 때문에 해당 변수는 스택에 할당된다.
슬라이스
make([]string,5)위의 코드를 실행하면 아래와 같은 이미지의 메모리 할당이 이뤄진다.

여기서 특이한 개념이 나오게 되는데 "길이와 용량이라는 개념이다."
make 함수를 이용해서 slice, map, channel을 생성할 수 있는데 여기서 3번째 키워드는 용량을 나타낸다.
길이는 포인터로부터 읽고 쓸 수 있는 수를 의미하지만, 용량은 포인터부터 배열에 존재할 수 있는 총량을 의미한다.
var data []string
data2 := []string{}두 개는 다르다. data는 빈 슬라이스지만 nil 포인터를 갖고 있는 비어이 있는 슬라이스가 된다.
nil 슬라이스 와 비어있는 슬라이스는 각기 다른 의미를 가진다. 제로값으로 설정된 참조 타입은 nil로 여길수 있다는 점이다.
marshal에 이 nil과 비어있는 슬라이스를 넘긴다면 json에서는 null과 [] 있는 각각의 슬라이스를 반환하게 된다.
append 함수의 특징상 capacity에 다다르면 새로운 메모리 주소를 할당한다.
func Test_SliceReference(t *testing.T) {
x := make([]int, 7)
for i := 0; i < len(x); i++ {
x[i] = i * 100
}
twoHundred := &x[1]
x = append(x, 800)
x[1]++
fmt.Println(x[1], *twoHundred)
}twoHundred와, x [1]은 다른 메모리 주소를 가진다. append를 사용해 7 이 넘은 슬라이스의 상태가 되어 새로운 메모리 주소가 할당된다.
UTF8의 경우 지난번 string에 대해서 언급한 것 string을 range로 조회할 때 단어 하나단위로 조회된다고 작성했다.
조금 더 예를 들어서 작성해 보자면
func Test_UTF8(t *testing.T) {
s := "세계 means world"
var buf [utf8.UTFMax]byte
for i, r := range s {
rl := utf8.RuneLen(r)
si := i + rl
copy(buf[:], s[i:si])
fmt.Printf("%2d: %q: codepoint: %#6x encode bytes : %#v\n", i, r, r, buf[:rl])
}
}
0: '세': codepoint: 0xc138 encode bytes : []byte{0xec, 0x84, 0xb8}
3: '계': codepoint: 0xacc4 encode bytes : []byte{0xea, 0xb3, 0x84}
6: ' ': codepoint: 0x20 encode bytes : []byte{0x20}
7: 'm': codepoint: 0x6d encode bytes : []byte{0x6d}
8: 'e': codepoint: 0x65 encode bytes : []byte{0x65}
9: 'a': codepoint: 0x61 encode bytes : []byte{0x61}
10: 'n': codepoint: 0x6e encode bytes : []byte{0x6e}
11: 's': codepoint: 0x73 encode bytes : []byte{0x73}
12: ' ': codepoint: 0x20 encode bytes : []byte{0x20}
13: 'w': codepoint: 0x77 encode bytes : []byte{0x77}
14: 'o': codepoint: 0x6f encode bytes : []byte{0x6f}
15: 'r': codepoint: 0x72 encode bytes : []byte{0x72}
16: 'l': codepoint: 0x6c encode bytes : []byte{0x6c}
17: 'd': codepoint: 0x64 encode bytes : []byte{0x64}한글은 3바이트이다. 보이는가? 또한 가리키는 코드포인트 또한 다르다.
'Go > Go Basic' 카테고리의 다른 글
| Ultimate-Go-04 [디커플링] (0) | 2023.09.13 |
|---|---|
| Ultimate-Go-03 (2) | 2023.09.07 |
| Ulitmate-Go-01 (string,메모리 패딩) (3) | 2023.08.19 |
| Go Interface, embedded (0) | 2023.02.28 |
| Effective Go 04 (0) | 2023.02.12 |